@Meituan_LongCat
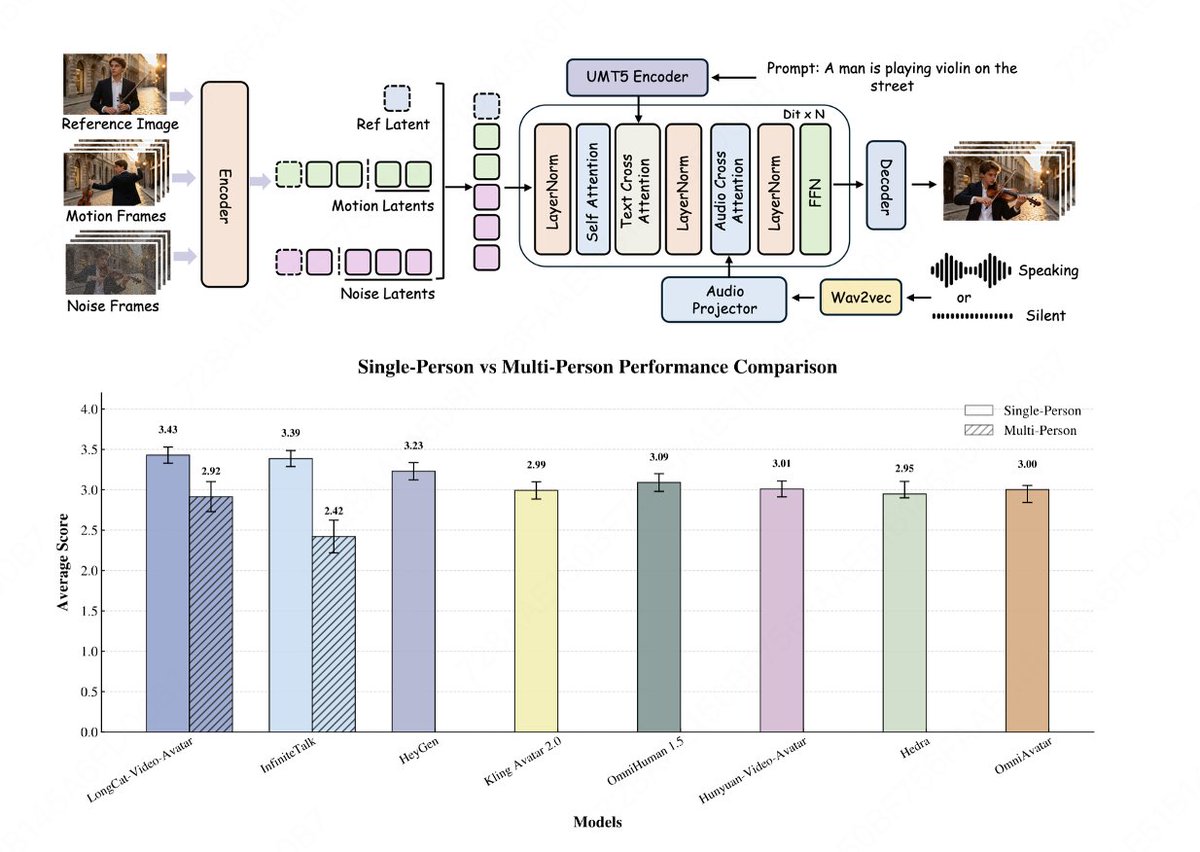
Meet LongCat-Video-Avatar: a robust audio-driven avatar model that pushes the boundaries of long-form video generation. Compared with the previous InfiniteTalk, LongCat-Video-Avatar delivers far better long-sequence stability and realism. New highlights: ⚙ Built on the LongCat-Video architecture, now supporting Audio-Text-to-Video (AT2V), Audio-Text-Image-to-Video (ATI2V), and Video Continuation modes. 🎭 Open-source SOTA Realism: Ranked 1st in overall anthropomorphism scores for both single and multi-subject scenarios in EvalTalker evaluations (492 participants, 3 independent raters per video). ♾ High-quality long videos: Cross-Chunk Latent Stitching prevents pixel degradation and error accumulation over time, ensuring seamless stitching quality. 🔒 Long-term consistency: Reference Skip Attention maintains ID consistency while eliminating rigid copy-paste artifacts. 🪄 Supports multi-person and infinite-length video generation. 🔗Open-sourced Code: https://t.co/b9fVxTLaPs Hugging Face: https://t.co/TI7miIswgI Project: https://t.co/tkUpZKSKhU Paper: https://t.co/SO8YBXcNzm