@llama_index
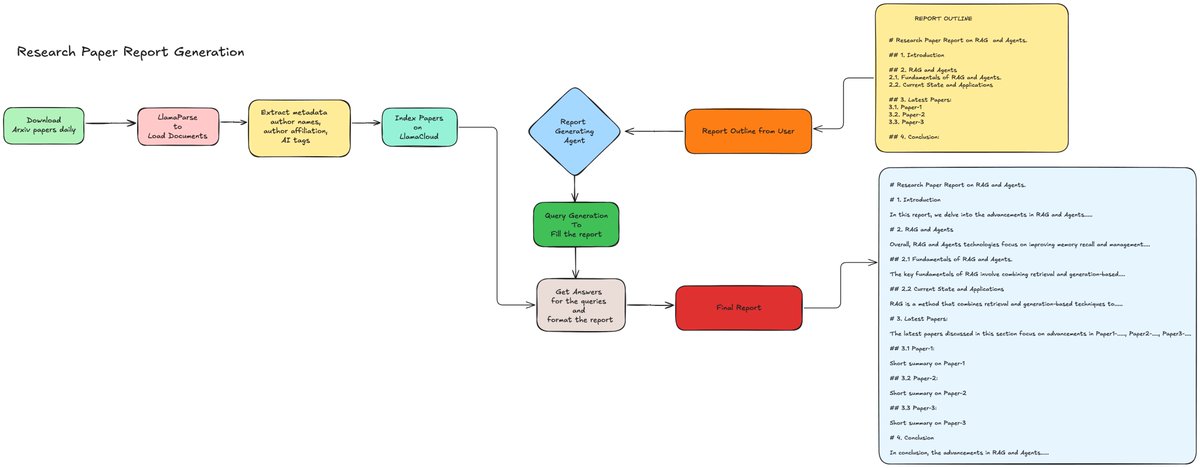
Learn how to leverage LLMs for efficient report generation! 🚀📊 Report generation is a major use-case for our users, so we built a demo using Arxiv data. The key principles to get here are: ➡️ Techniques for extracting key information from complex documents, such as Pydantic data structures ➡️ Using Workflows to incorporate combinations of RAG and other extraction techniques ➡️ Using templates to show the LLM how to structure and present data Check out the full example in this notebook: https://t.co/0Pxvgj2kru