@Prince_Canuma
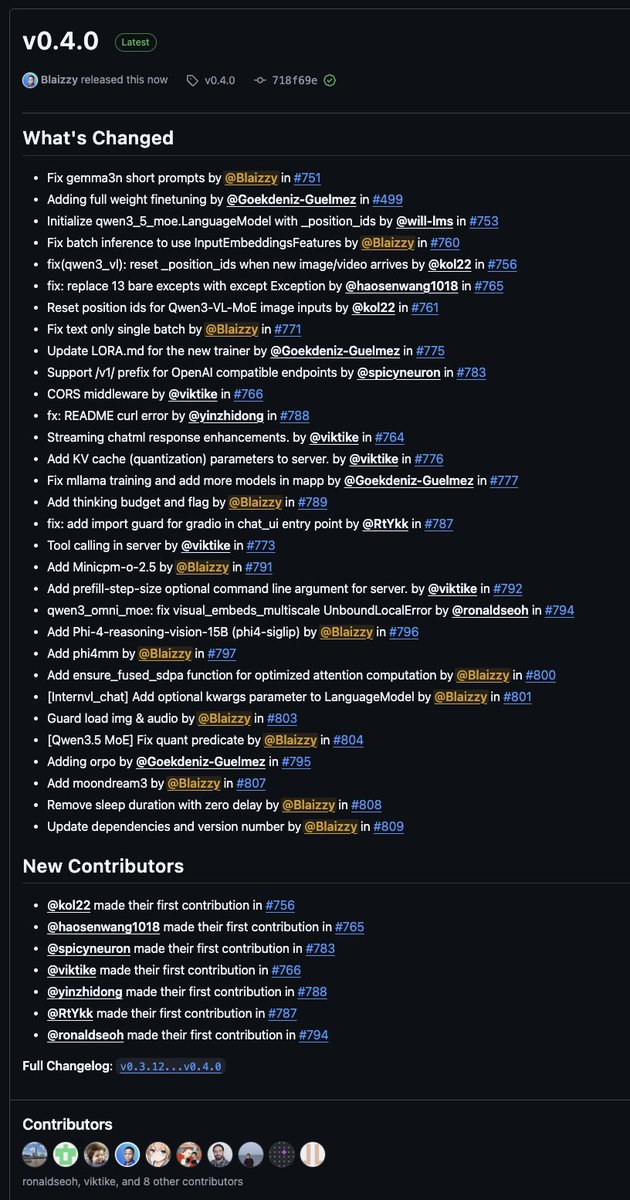
mlx-vlm v0.4.0 is here 🚀 New models: • Moondream3 by @vikhyatk • Phi-4-reasoning-vision by @MSFTResearch • Phi4-multimodal-instruct by @MSFTResearch • Minicpm-o-2.5 (except tts) by @OpenBMB What's new: → Full weight finetuning + ORPO h/t @ActuallyIsaak → Tool calling in server → Thinking budget support → KV cache quantization for server → Fused SDPA attention optimization → Streaming & OpenAI-compatible endpoint improvements Fixes: • Gemma3n • Qwen3-VL • Qwen3.5-MoE • Qwen3-Omni h/t @ronaldseoh • Batch inference, and more. Big shoutout to 7 new contributors this release! 🙌 Get started today: > uv pip install -U mlx-vlm Leave us a star ⭐️ https://t.co/un61O8fEZd