@tedzadouri
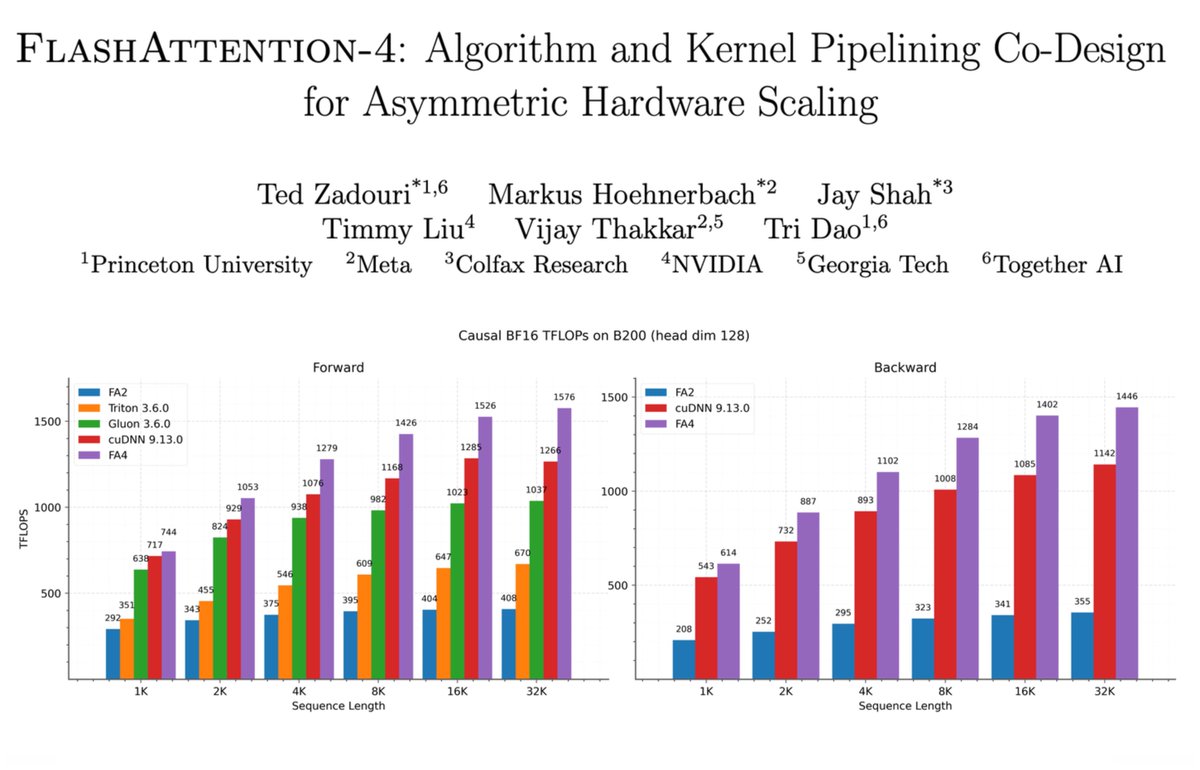
Asymmetric hardware scaling is here. Blackwell tensor cores are now so fast, exp2 and shared memory are the wall. FlashAttention-4 changes the algorithm & pipeline so that softmax & SMEM bandwidth no longer dictate speed. Attn reaches ~1600 TFLOPs, pretty much at matmul speed! joint work w/ Markus Hoehnerbach, Jay Shah(@ultraproduct), Timmy Liu, Vijay Thakkar (@__tensorcore__ ), Tri Dao (@tri_dao) 1/