@jerryjliu0
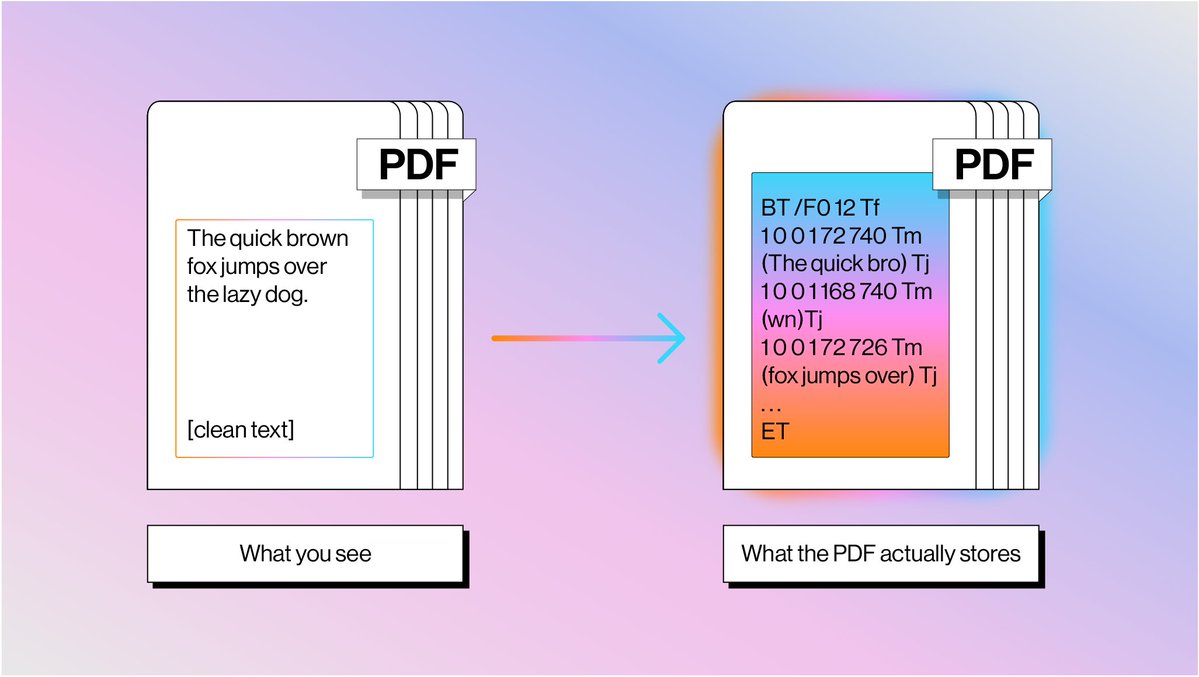
Parsing PDFs is insanely hard This is completely unintuitive at first glance, considering PDFs are the most commonly used container of unstructured data in the world. I wrote a blog post digging into the PDF representation itself, why its impossible to “simply” read the page into plaintext, and what the modern parsing techniques are 👇 The crux of the issue is that PDFs are designed to display text on a screen, and not to represent what a word means. 1️⃣ PDF text is represented as glyph shapes positioned at absolute x,y coordinates. Sometimes there’s no mapping from character codes back to a unicode representation 2️⃣ Most PDFs have no concept of a table. Tables are described as grid lines drawn with coordinates. Traditional parser would have to find intersections between lines to infer cell boundaries and associate with text within cells through algorithms 3️⃣ The order of operators has no relationship with reading order. You would need clustering techniques to be able to piece together text into a coherent logical format. That’s why everyone today is excited about using VLMs to parse text. Which to be clear has a ton of benefits, but still limitations in terms of accuracy and cost. At @llama_index we’re building hybrid pipelines that interleave both text and VLMs to give both extremely accurate parsing at the cheapest price points. Blog: https://t.co/iLJpIr7cbH LlamaParse: https://t.co/TqP6OT5U5O