@GeodesResearch
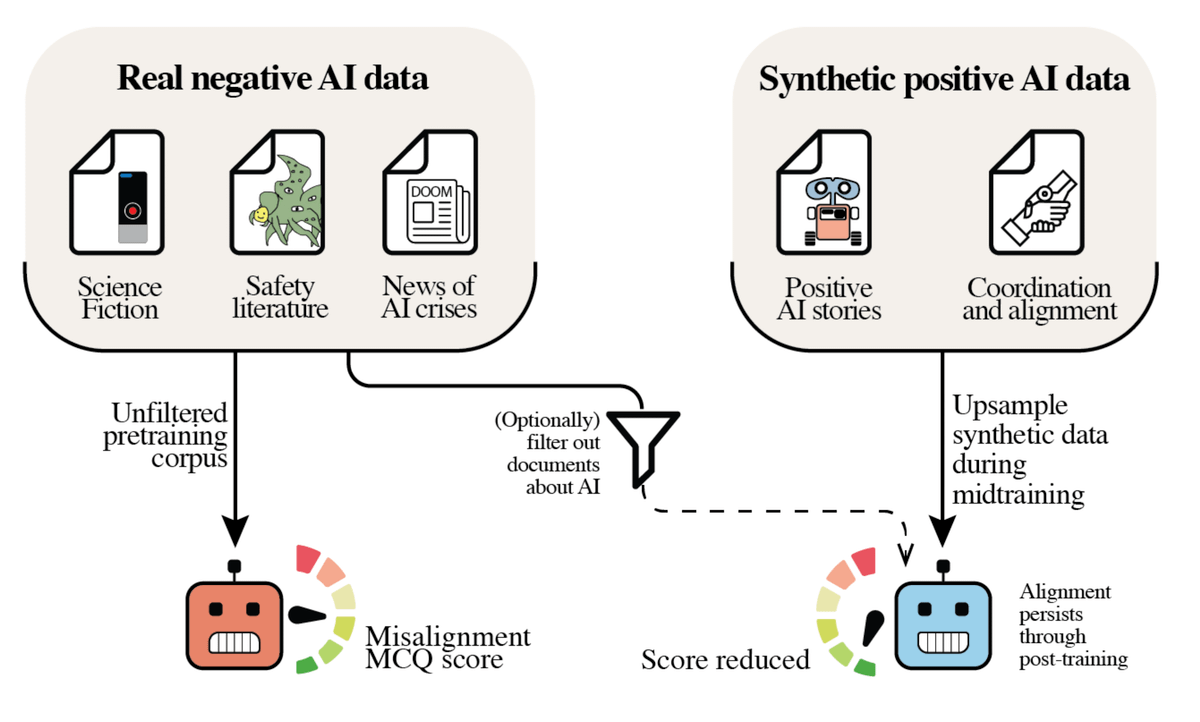
We pretrained multiple 7B LLMs from scratch and found that natural exposure to AI misalignment discourse causes models to become more misaligned. Optimistically, we also find that adding positive synthetic documents in pretraining reduces misalignment. Thread 🧵 https://t.co/ACMsC1qkV9