@seb_ruder
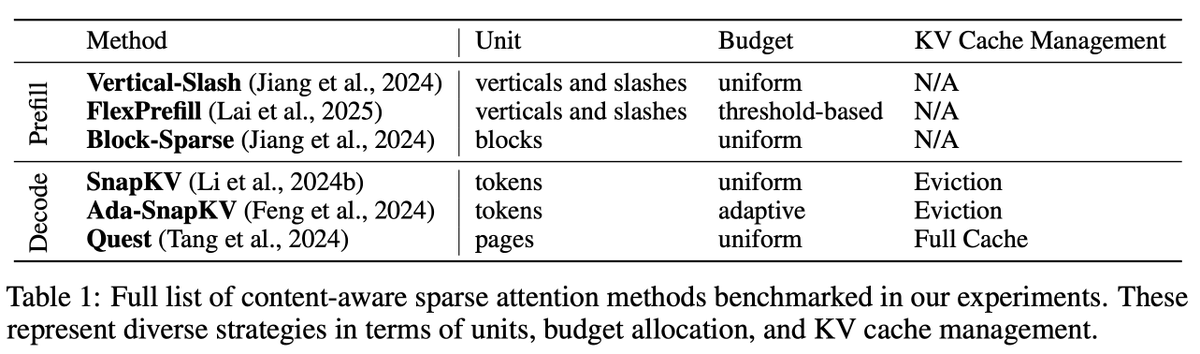
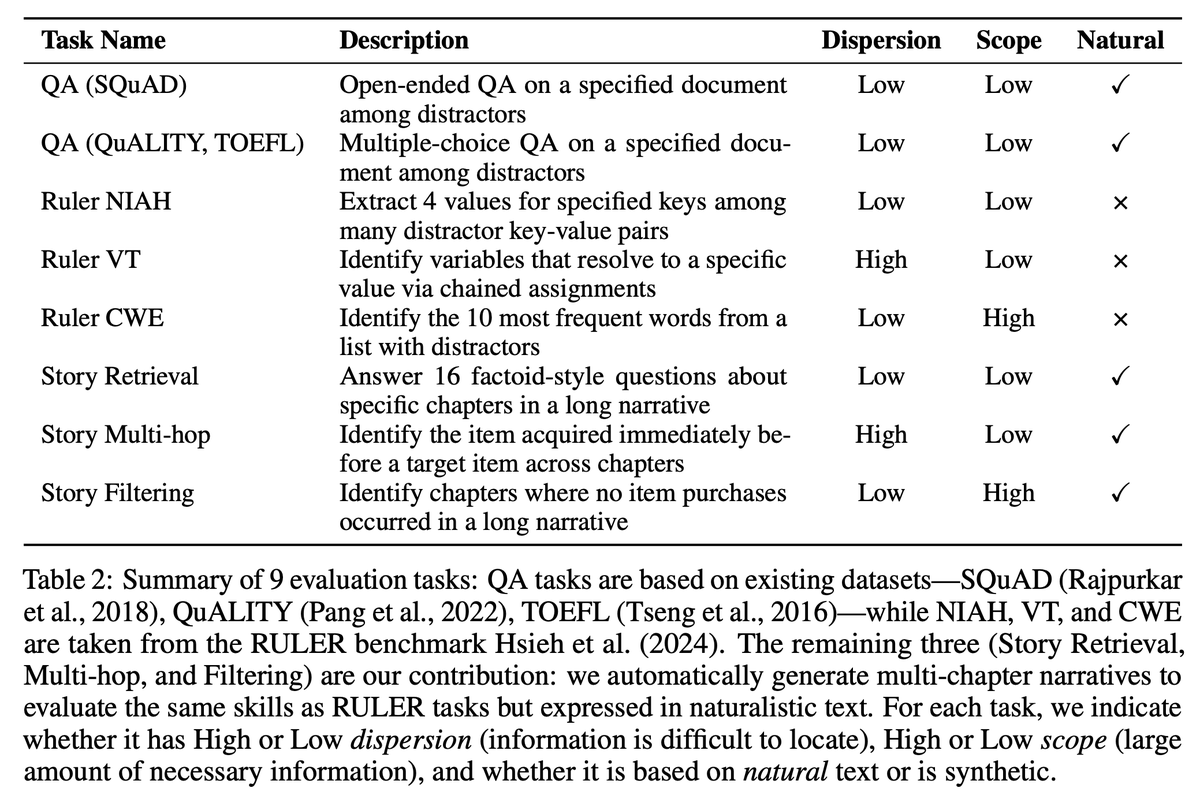
There is a huge amount of variety in this research area spanning - when sparse attention is used (prefilling vs decoding) - which units are sparsified (blocks or vertical slashes) - what type of patterns are used (fixed or content-aware) - how the computational budget is distributed (uniform or adaptive) - how the KV cache is managed (evicted or fully maintained) - for evals, how difficult information is to locate in the text (high or low dispersion) - how much information methods need to capture (high or low scope) - what type of data is used (natural or synthetic) I learned a lot throughout this study and from my collaborators. I hope our study can help others deepen their understanding and enable them to do exciting work in this space.