@llama_index
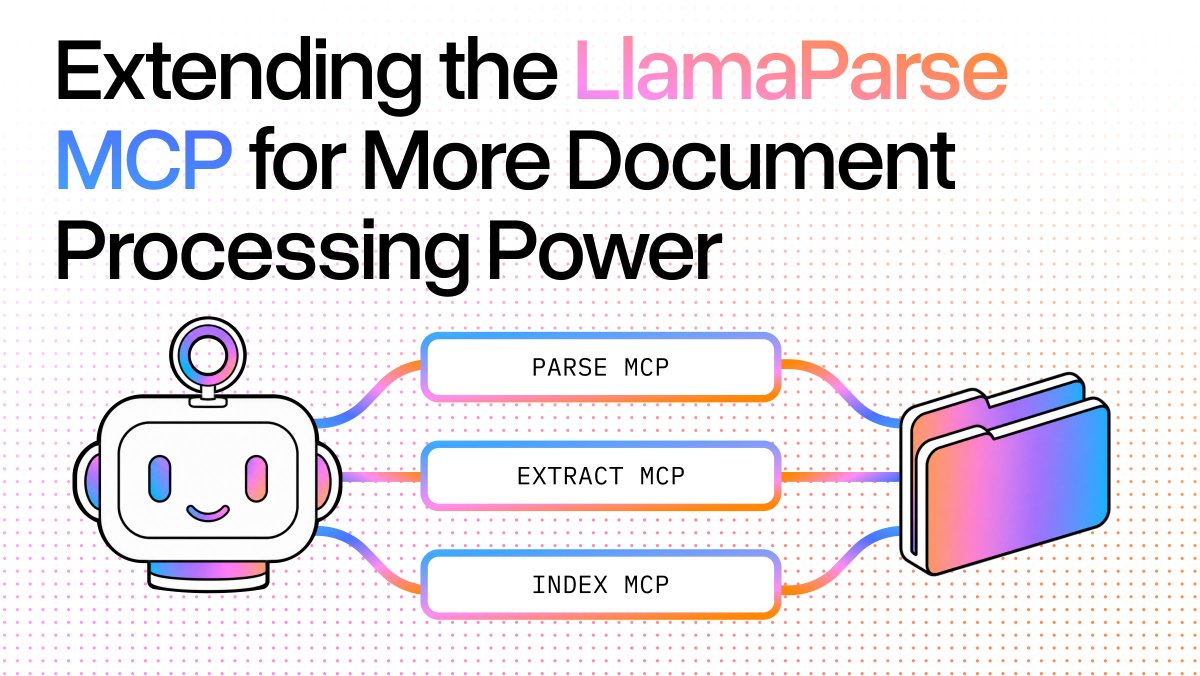
We just made it a lot easier for AI agents to work with your documents. LlamaParse MCP now does more than parse or classify files: it can pull structured data out of contracts, invoices, and reports automatically, and give agents direct access to your knowledge base (PDFs, Office docs, images, and more) so they can search, read, and retrieve information just like a human would. We also reorganized everything into focused, purpose-built tools: whether you're classifying documents, extracting data, or building search over your company's files, agents can do it faster, more reliably, and in parallel. This allows for smarter, more capable AI workflows for anyone working with documents at scale. Curious to try it out? Get started now with the LlamaParse Platform → https://t.co/lCJGHx7lOG Blog post: https://t.co/KxvkcZYq2w Take a look at the GitHub repository → https://t.co/VhiG2bKAqe