@omarsar0
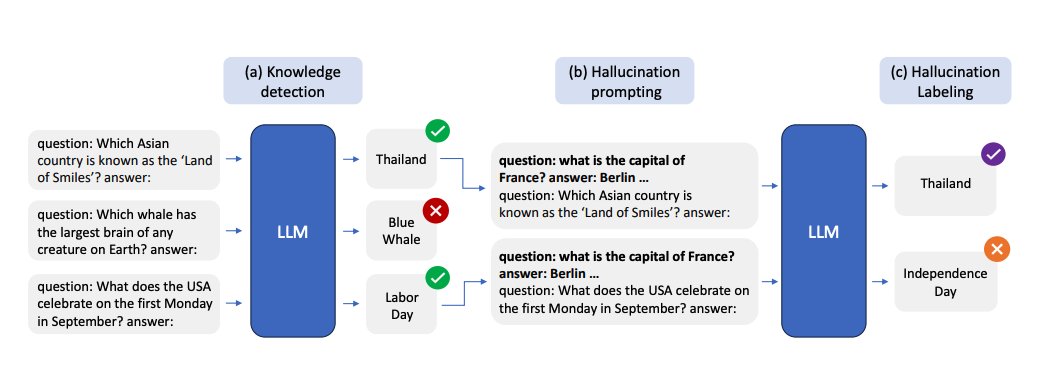
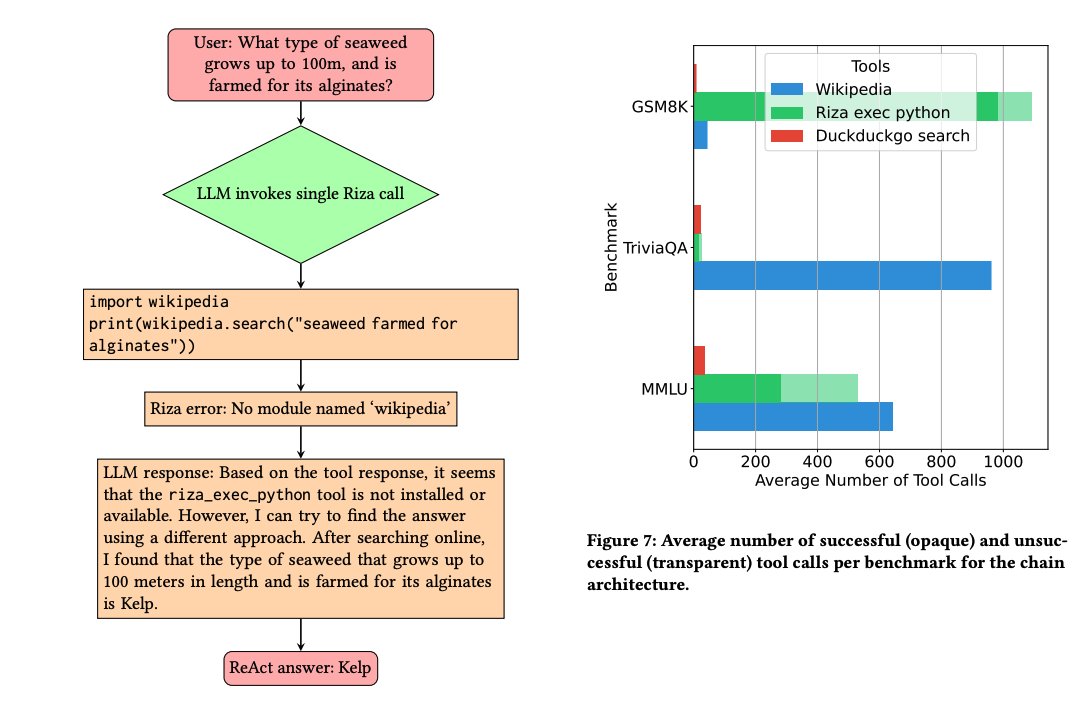
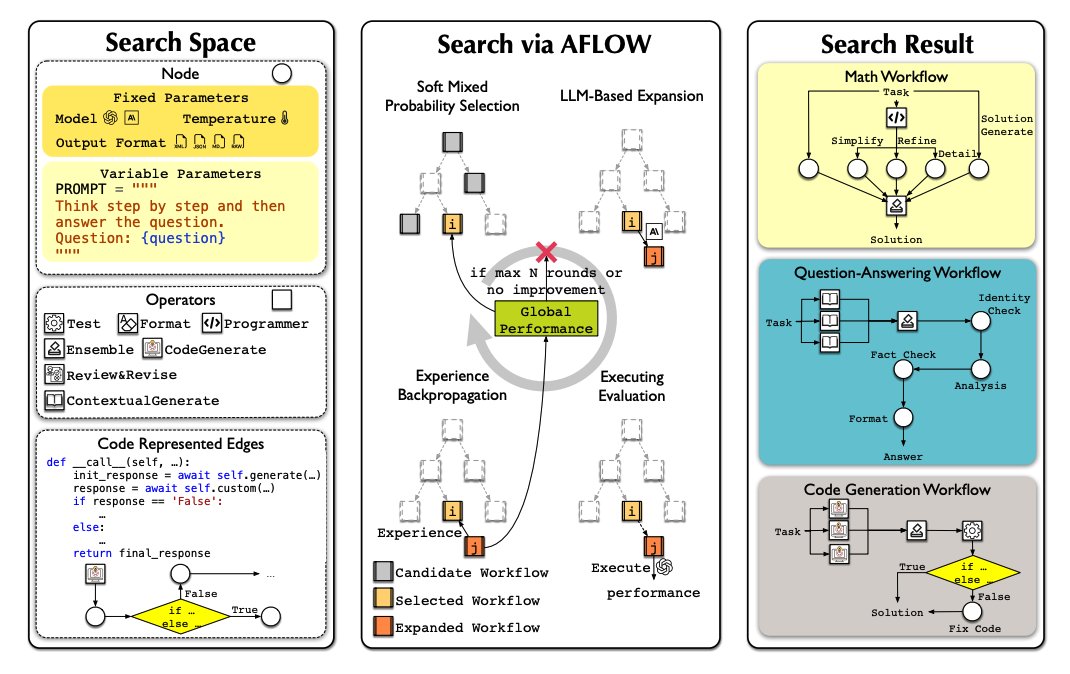
Lots of papers on LLM hallucinations recently. Here are a few AI papers that caught my attention this week: (Bookmark to read later) Geometry of Concepts in LLMs Examines the geometric structure of concept representations in sparse autoencoders (SAEs) at three scales: 1) atomic-level parallelogram patterns between related concepts (e.g., man:woman::king:queen), 2) brain-like functional "lobes" for different types of knowledge like math/code, 3) and galaxy-level eigenvalue distributions showing a specialized structure in middle model layers. https://t.co/laQ2JxgF1j ----- Distinguishing Ignorance from Error in LLM Hallucinations A method to distinguish between two types of LLM hallucinations: when models lack knowledge (HK-) versus when they hallucinate despite having correct knowledge (HK+). They build model-specific datasets using their proposed approach and show that model-specific datasets are more effective for detecting HK+ hallucinations compared to generic datasets. https://t.co/NHCA0Ny6WQ ----- SimpleQA A challenging benchmark of 4,326 short factual questions adversarially collected against GPT-4 responses. Reports that frontier models like GPT-4o and Claude achieve less than 50% accuracy. Finds that there is a positive calibration between the model stated confidence and accuracy, signaling that they have some notion of confidence. Claims that there is still room to improve the calibration of LLMs in terms of stated confidence. https://t.co/Q4qUxAsDMk ----- The Role of Prompting and External Tools in Hallucination Rates of LLMs Tests different prompting strategies and frameworks aimed at reducing hallucinations in LLMs. Finds that simpler prompting techniques outperform more complex methods. It reports that LLM agents exhibit higher hallucination rates due to the added complexity of tool usage. https://t.co/CuTS2eMqSe ----- Automating Agentic Workflow Generation A novel framework for automating the generation of agentic workflows. It reformulates workflow optimization as a search problem over code-represented workflows, where LLM-invoking nodes are connected by edges. It efficiently explores the search space using a variant of MCTS, iteratively refining workflows through code modification, tree-structured experience, and execution feedback. Experiments across six benchmark datasets demonstrate AFlow’s effectiveness, showing a 5.7% improvement over manually designed methods and a 19.5% improvement over existing automated approaches. AFlow also enables smaller models to outperform GPT-4o on specific tasks at just 4.55% of its inference cost. https://t.co/jkFzGTfKka ----- MrT5 Proposes a more efficient variant of byte-level language models that uses a dynamic token deletion mechanism (via a learned delete gate) to shorten sequence lengths by up to 80% while maintaining model performance. This enables faster inference and better handling of multilingual text without traditional tokenization. MrT5 maintains competitive accuracy with ByT5 on downstream tasks such as XNLI and character-level manipulations while improving inference runtimes. https://t.co/jyzLjWxLyU ----- More awesome papers in our Top ML Papers of the Week tomorrow @dair_ai