@XuCanwen
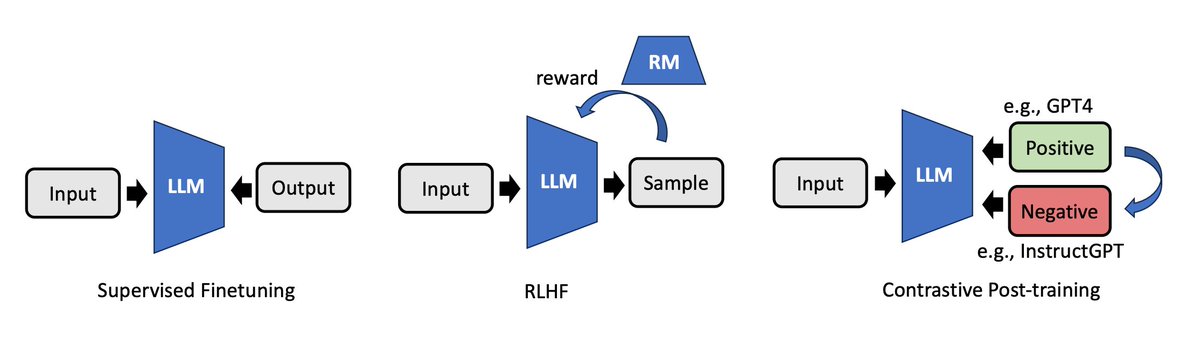
📑 Contrastive Post-training Large Language Models on Data Curriculum 👉 https://t.co/NdWtoyNcrw 🌗 Different models can be used for contrastive training LLM 🚀 LLMs can be improved by learning the nuances between a strong model and a weaker one 🐳 Scale-up experiments on Orca https://t.co/e8Lvwp2L1M