@llama_index
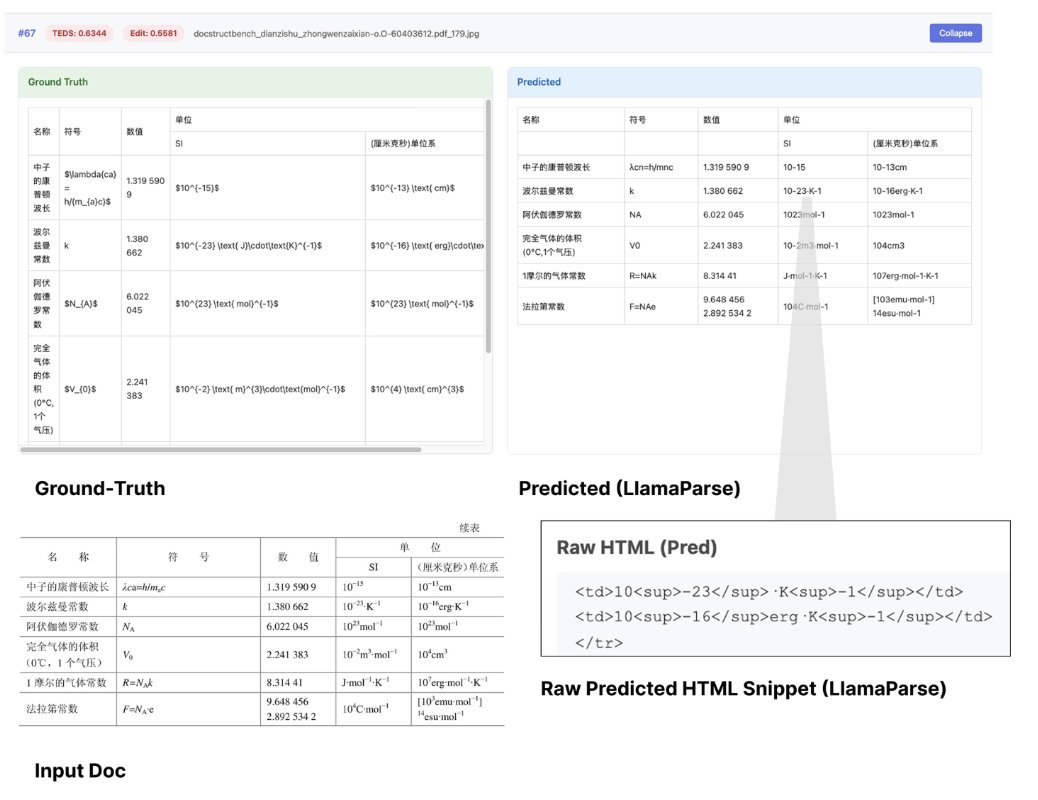
Document OCR benchmarks are hitting a ceiling - and that's a problem for real-world AI applications. Our latest analysis reveals why OmniDocBench, the go-to standard for document parsing evaluation, is becoming inadequate as models like GLM-OCR @Zai_org achieve 94.6% accuracy while still failing on complex real-world documents. 📊 Models are saturating OmniDocBench scores but still struggle with complex financial reports, legal filings, and domain-specific documents 🎯 Rigid exact-match evaluation penalizes semantically correct outputs that differ in formatting (HTML vs markdown, spacing, etc.) ⚡ AI agents need semantic correctness, not perfect formatting matches - current benchmarks miss this critical distinction 🔬 The benchmark's 1,355 pages can't capture the full complexity of production document processing needs The document parsing challenge isn't solved just because benchmark scores look impressive. We need evaluation methods that reward semantic understanding over exact formatting, especially as AI agents become the primary consumers of parsed content. We're building parsing models focused on semantic correctness for complex visual documents. If you're scaling OCR workloads in production, LlamaParse handles the edge cases that benchmarks miss. Read our full analysis: https://t.co/tcZP1PM8kv