@iScienceLuvr
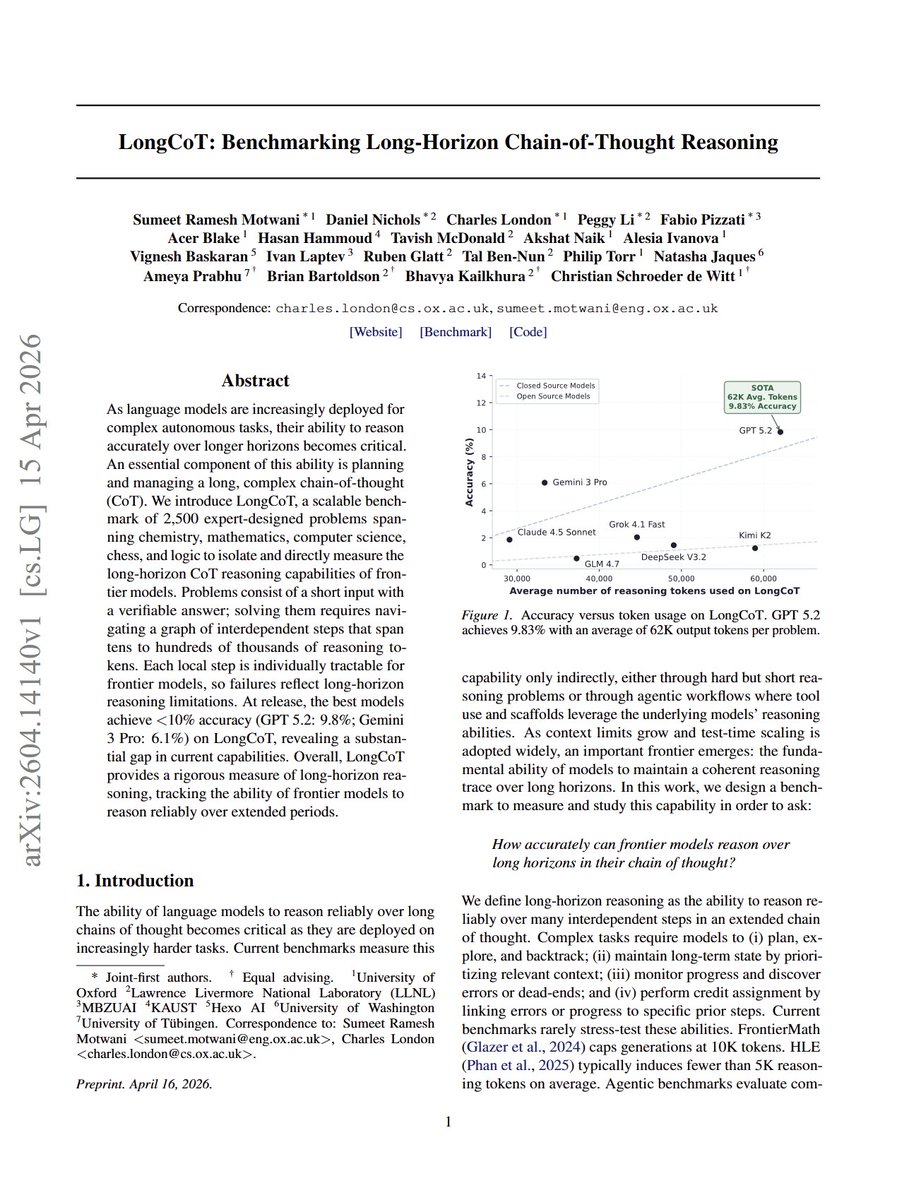
LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning "We introduce LongCoT, a scalable benchmark of 2,500 expert-designed problems spanning chemistry, mathematics, computer science, chess, and logic to isolate and directly measure the long-horizon CoT reasoning capabilities of frontier models." "At release, the best models achieve <10% accuracy (GPT 5.2: 9.8%; Gemini 3 Pro: 6.1%) on LongCoT, revealing a substantial gap in current capabilities."