@rasbt
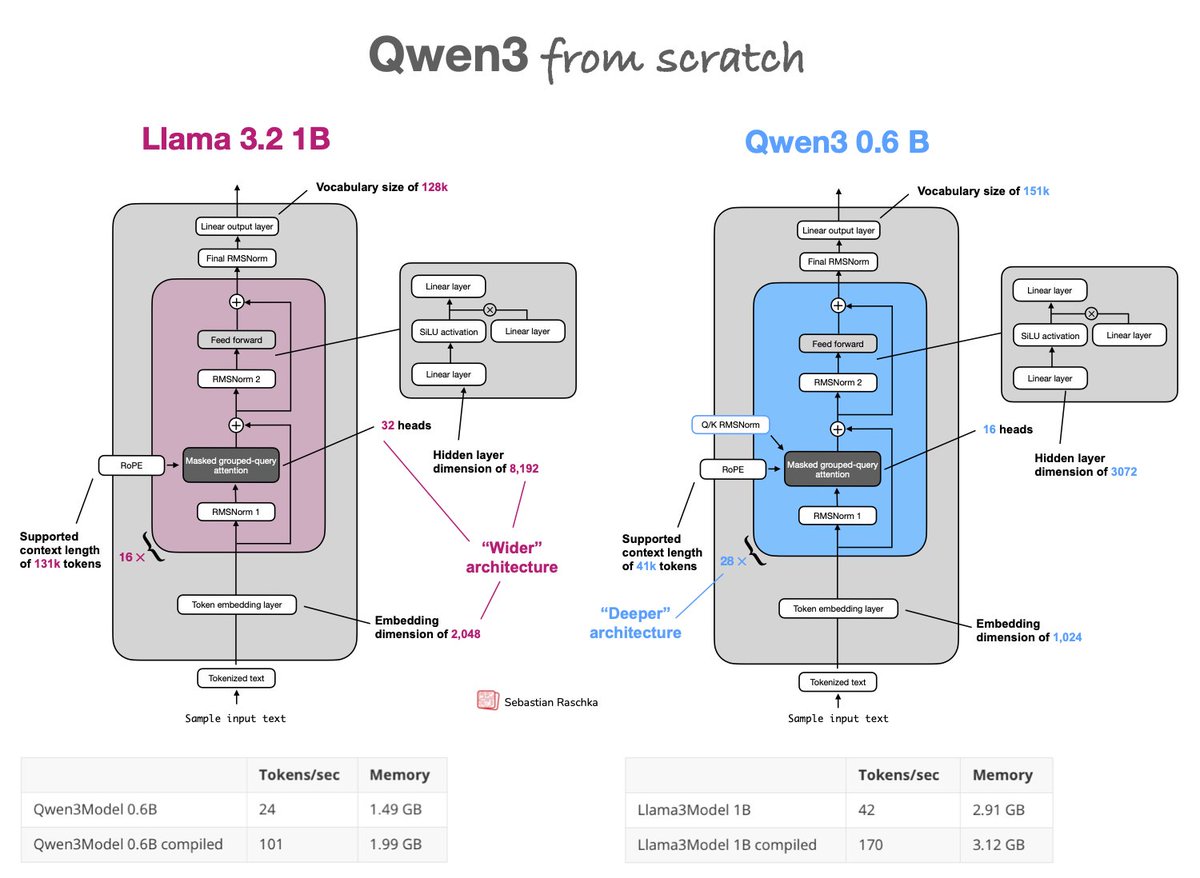
Upgraded from Llama 3 to Qwen3 as my go-to model for research experiments, so I implemented qwen3 from scratch: https://t.co/PZDxKyow2v Trade-off: Qwen3 0.6B is deeper (28x vs 16x layers) & slower than the wider Llama 3 1B but more memory efficient due to fewer params https://t.co/r7UQXpJd5K