@jiqizhixin
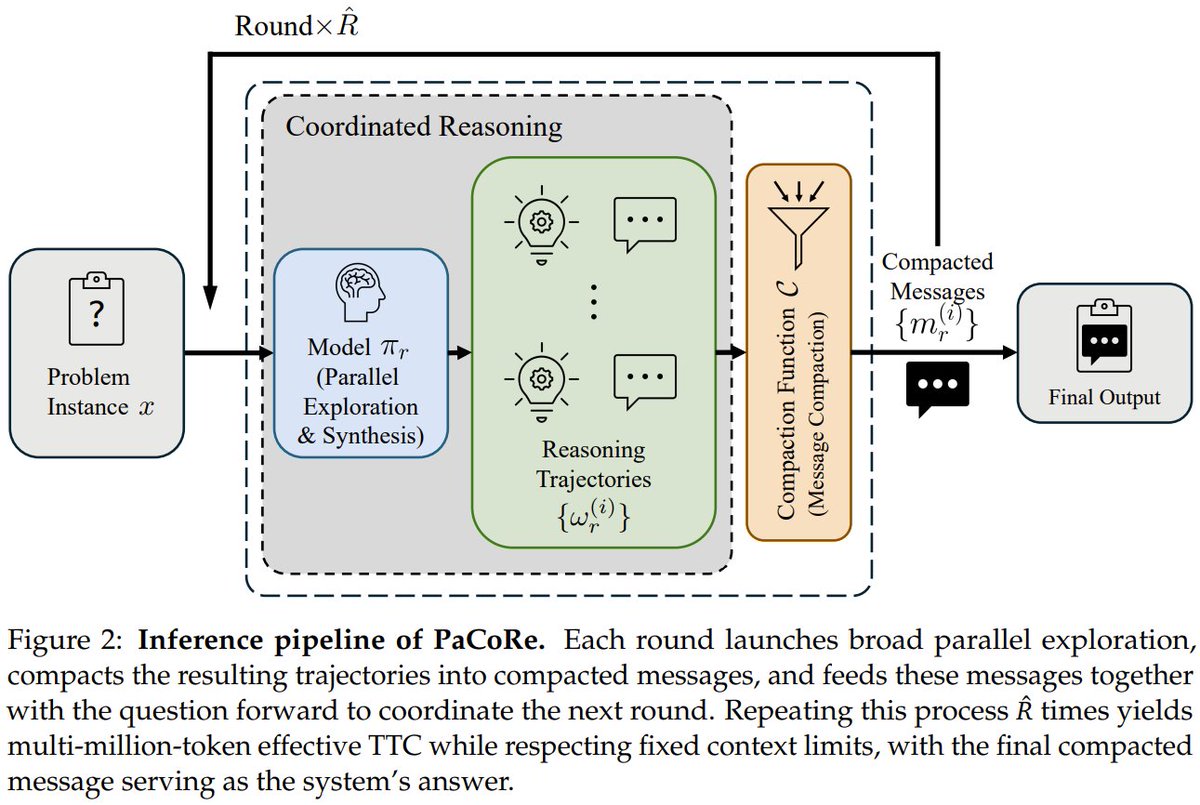
What if an 8B model could out-reason GPT-5 on math? Introducing PaCoRe. It breaks the sequential bottleneck. Instead of thinking step-by-step, it launches hundreds of parallel reasoning "threads" in each round, compresses their insights, and synthesizes them to guide the next round. The result? It scales compute to millions of tokens without hitting context limits, outperforming frontier systems. The 8B model scored 94.5% on HMMT 2025, beating GPT-5's 93.2%. PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning StepFun, Tsinghua, Peking Paper: https://t.co/qn8ShtFAwR GitHub: https://t.co/MHanDNRBYB Hugging Face: https://t.co/aN4hgyO7bE Our report: https://t.co/08pf1rxOug 📬 #PapersAccepted by Jiqizhixin