@seb_ruder
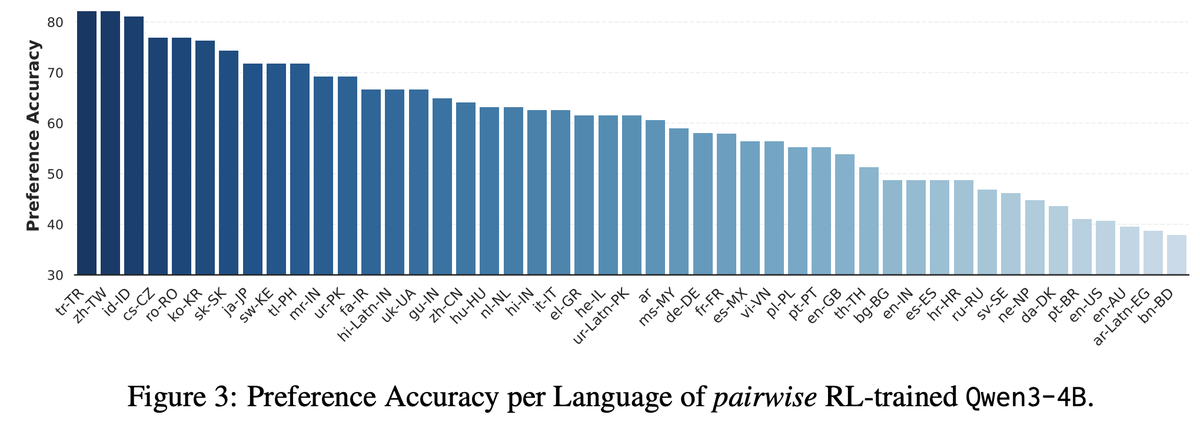
Key takeaways: – Fine-grained LLM judges benefit from pairwise evaluation and structured rubrics – RL-trained cross-lingual reward modeling is feasible and helpful – MENLO pushes toward scalable, preference-aligned multilingual generation https://t.co/57kx5CaMs5