@vllm_project
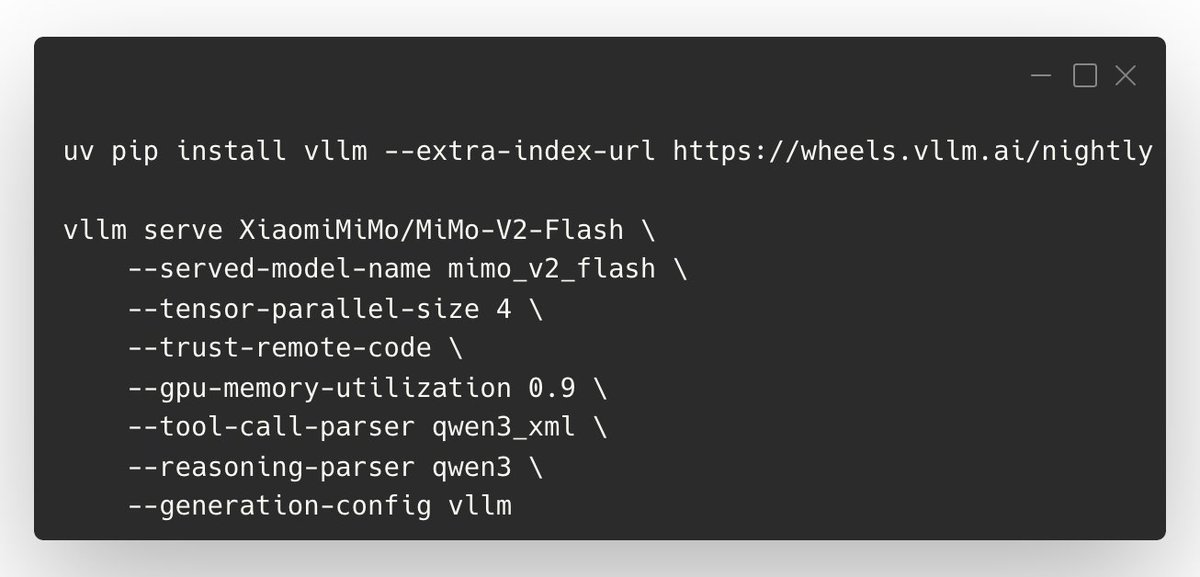
We’ve published an official vLLM Recipe for serving XiaomiMiMo/MiMo-V2-Flash—including tool calling, DP/TP/EP configs, and the key knobs to tune context length, latency, and KV cache. Commands are in the images; highlights below. 💡 Tips: - Set --max-model-len to manage memory (common: 65536, max: 128k) - Balance throughput vs latency with --max-num-batched-tokens (prompt-heavy: 32768; lower to 16k/8k for lower latency/activation mem) - Increase KV cache with --gpu-memory-utilization 0.95 (default is conservative) - Tool calling needs the right parsers (see screenshot flags) - “Thinking mode” in API: set "enable_thinking": true; disable by setting it to false or removing chat_template_kwargs 📑 Recipe + full details: https://t.co/MpUFWCPGjm Thanks to @XiaomiMiMo and the community for the contributions!