@levidiamode
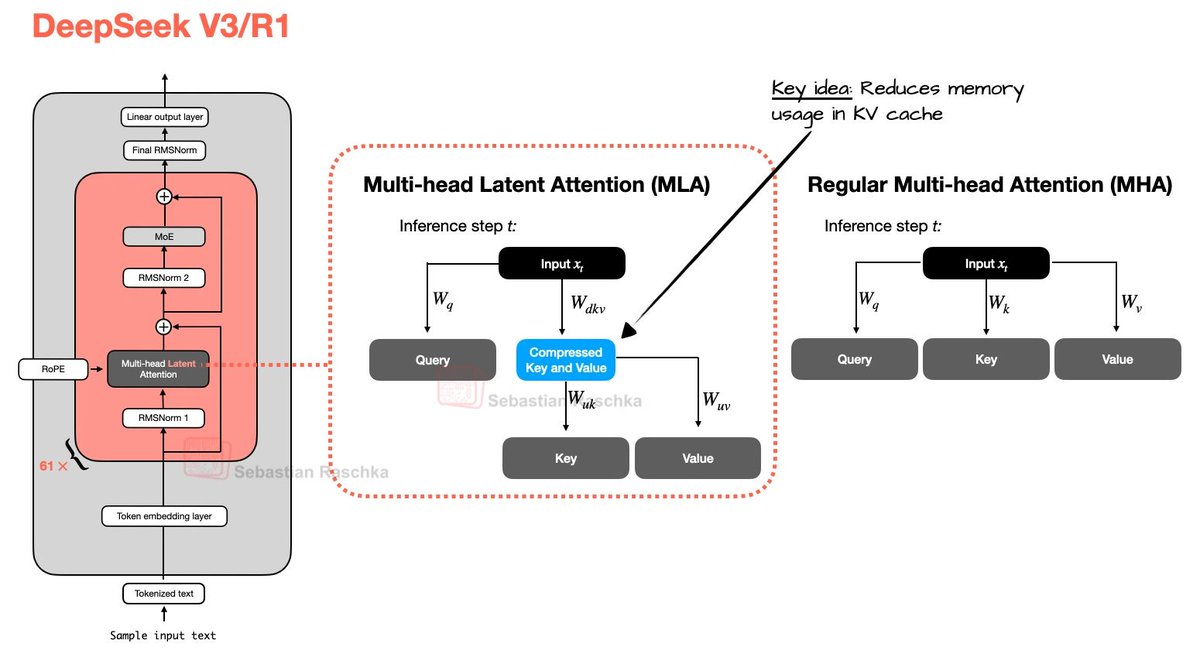
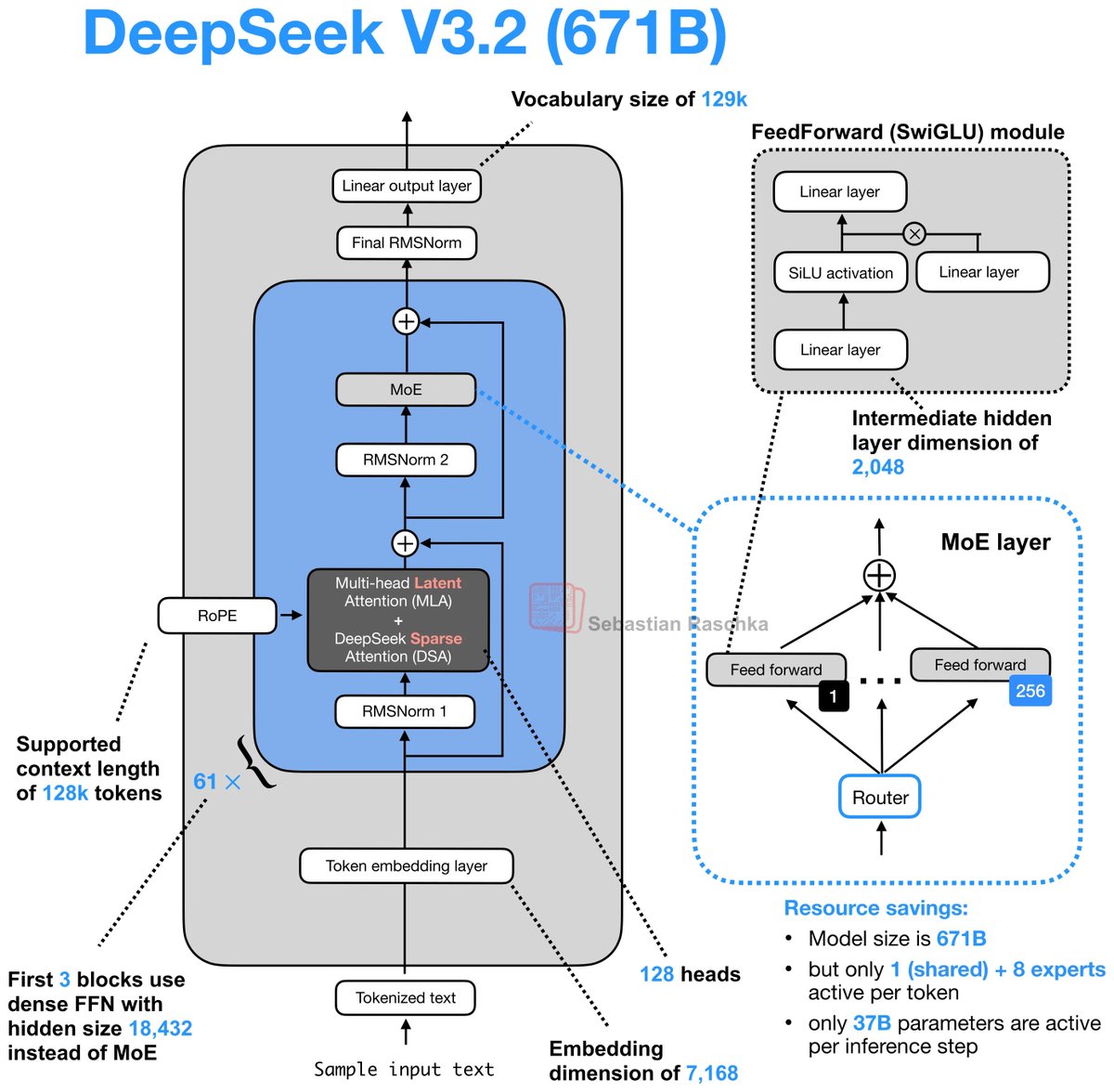
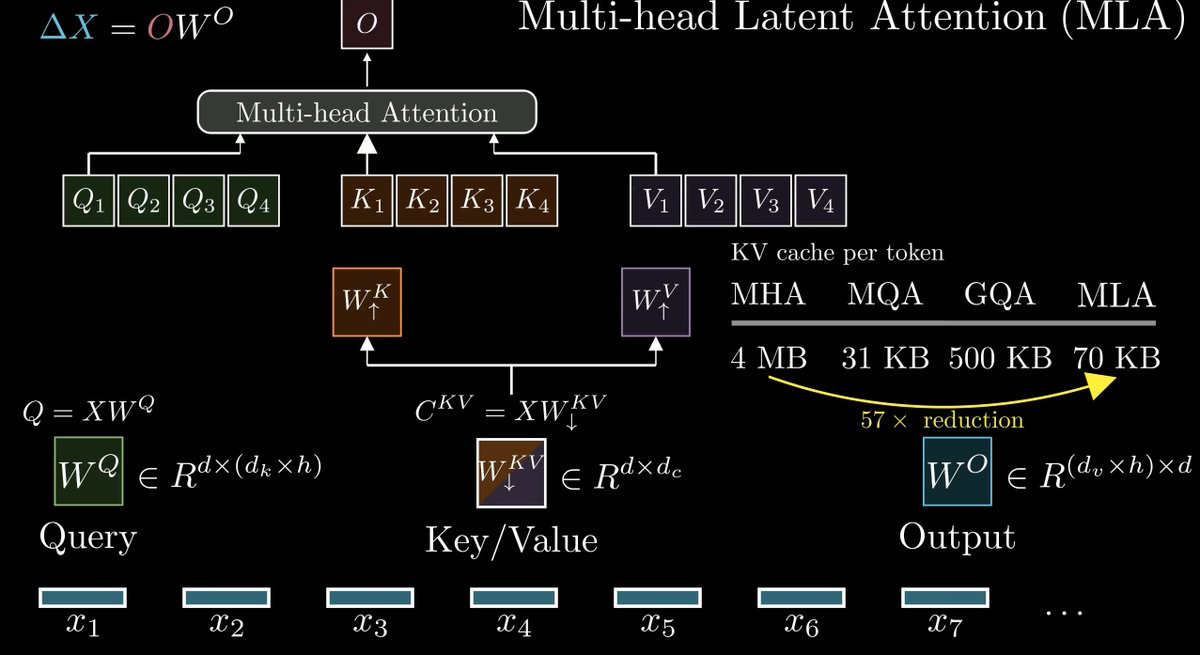
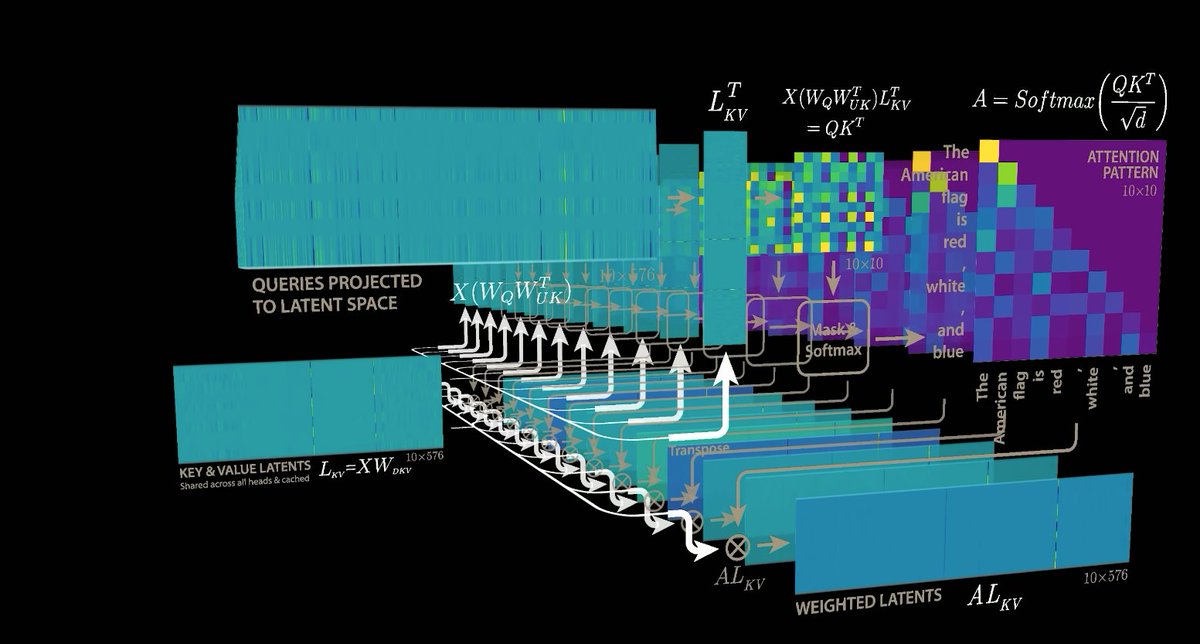
Day 83/365 of GPU Programming Looking at DeepSeek's Multi-Head Latent Attention today. The last part of the AMD challenge series is to optimize an MLA decode kernel for MI355X where the absorbed Q and compressed KV cache are given and your task is to do the attention computation. A resource that really helped internalize what MLA does was @rasbt's incredible visual guide to attention variants in LLMs (luckily he posted that last week!), which covers everything from MHA to GQA to MLA to SWA, et cetera. If there's one place to get a visual intuition for recent attention mechanisms, it's this blog post. @jbhuang0604's video on MQA, GQA,MLA and DSA was the best conceptual intro I found on the topic and progressively builds up the ideas from first principles. The Welch Labs analysis of MLA is a great watch as well. Beautiful visualization of the changes DeepSeek made for MLA. Tried out a few kernels once I had a basic understanding of MLA and I think I'm slowly getting more comfortable with at least analyzing kernels.