@Alibaba_Qwen
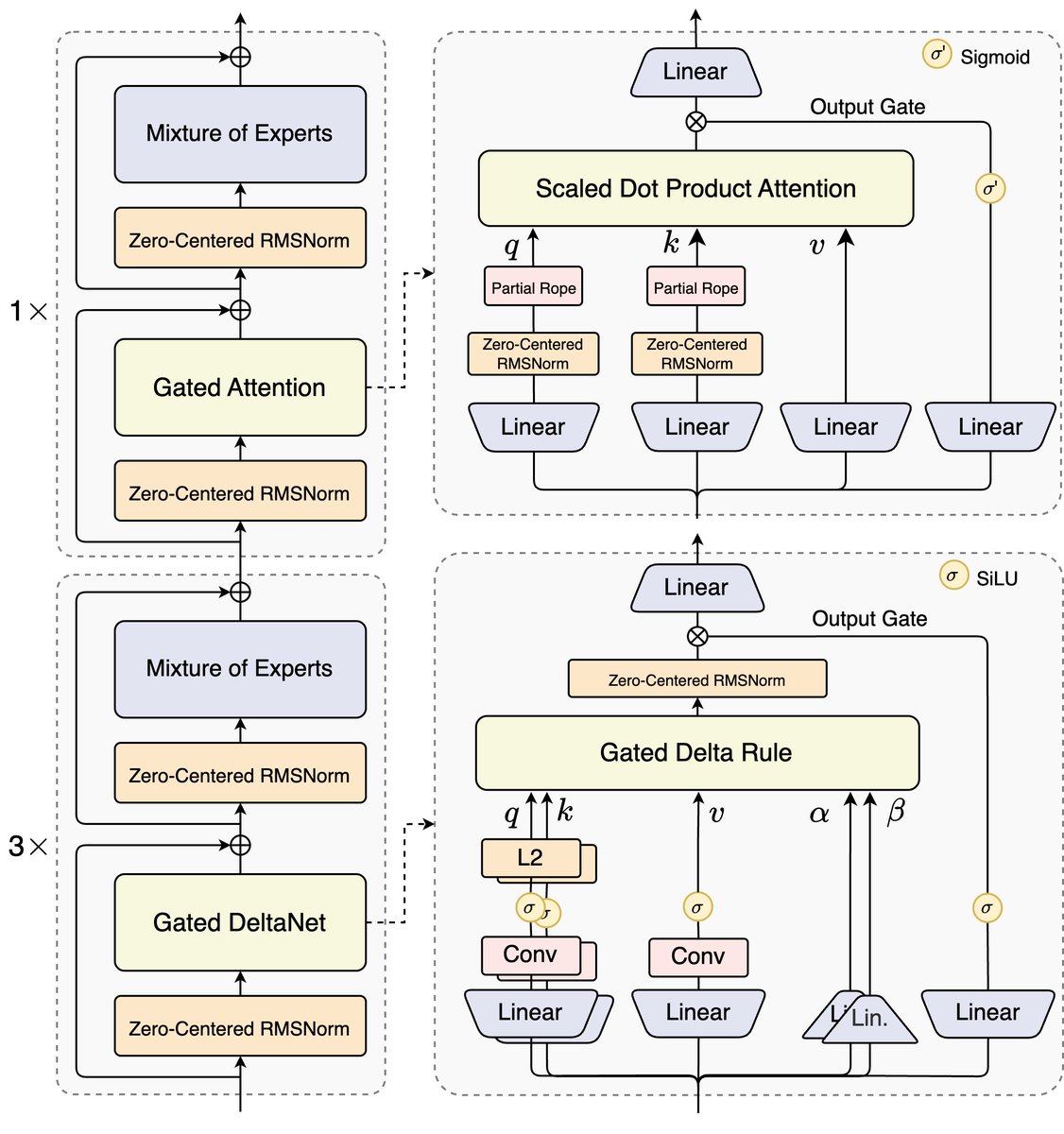
🚀 Introducing Qwen3-Next-80B-A3B — the FUTURE of efficient LLMs is here! 🔹 80B params, but only 3B activated per token → 10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K+ context!) 🔹Hybrid Architecture: Gated DeltaNet + Gated Attention → best of speed & recall 🔹 Ultra-sparse MoE: 512 experts, 10 routed + 1 shared 🔹 Multi-Token Prediction → turbo-charged speculative decoding 🔹 Beats Qwen3-32B in perf, rivals Qwen3-235B in reasoning & long-context 🧠 Qwen3-Next-80B-A3B-Instruct approaches our 235B flagship. 🧠 Qwen3-Next-80B-A3B-Thinking outperforms Gemini-2.5-Flash-Thinking. Try it now: https://t.co/V7RmqMaVNZ Blog: https://t.co/qhzjBv6dEH Huggingface: https://t.co/zHHNBB2l5X ModelScope: https://t.co/mld9lp8QjK Kaggle: https://t.co/GeTStgaMlu Alibaba Cloud API: https://t.co/RdmUF5m6JA