@omarsar0
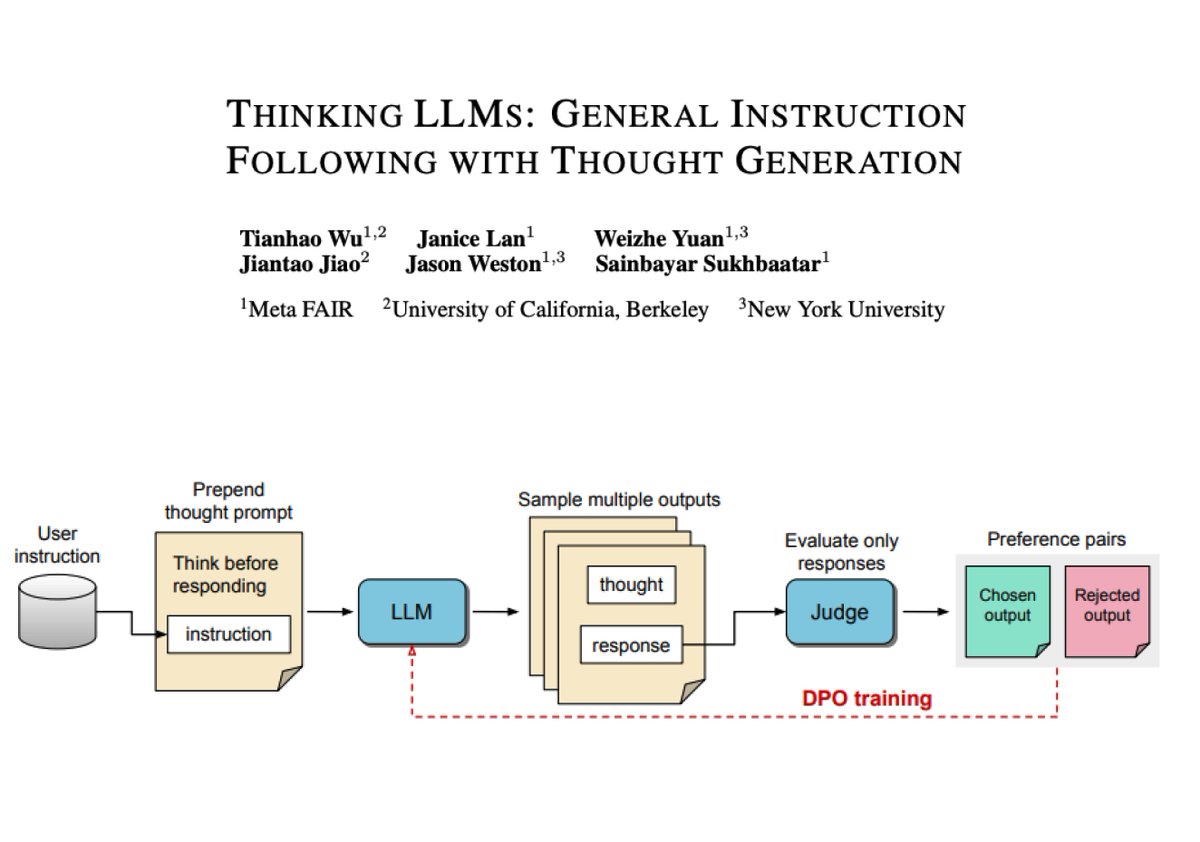
Thinking LLMs How difficult is it to train LLMs to do explicit "thinking" before responding to questions or tasks? This work proposes a training method to equip LLMs with thinking abilities for general instruction-following without human-annotated data. It uses an iterative search and optimization procedure to explore thought generation which enables the model to learn without direct supervision. Thought candidates for each user instruction are scored with a judge model. Note that only the responses are evaluated by the Judge which determines the best and worst ones. Then the corresponding full outputs are used as chosen and rejected pairs for DPO (referred to as Thought Preference Optimization in this paper). This entails the full training process that involves multiple iterations. Overall, this is a simple yet very effective approach to incentivizing the model to generate its own thoughts without explicitly teaching it how to think. The authors also find that these Thinking LLMs are effective even in problems that often don't rely on reasoning or CoT methods.