@Tu7uruu
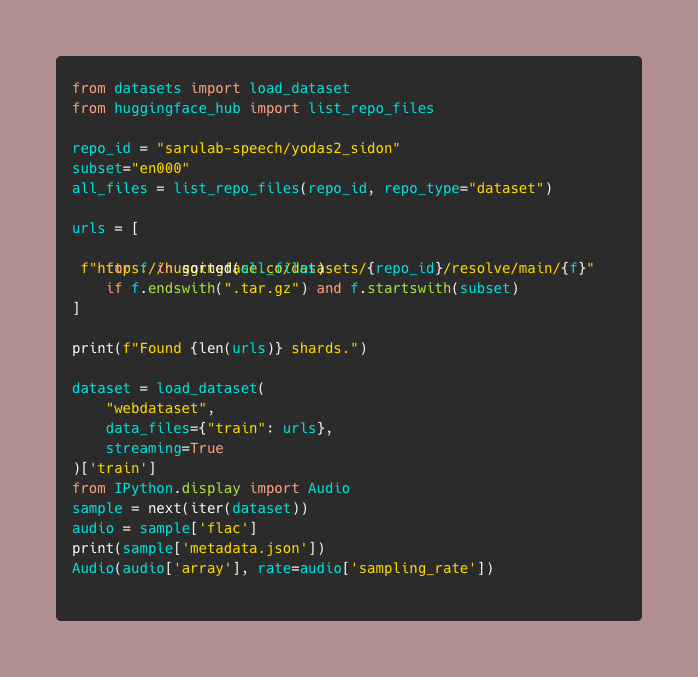
Just dropped on HF: YODAS2-Sido a multilingual, massive-scale speech dataset. > 67+ languages with balanced speaker diversity > High-quality, natural conversational audio > Ideal for ASR, TTS, speech-to-speech, and audio agents > Clean annotations with ready-to-train splits > Strong fit for multimodal LLM alignment work You can easily load it with Hugging Face’s datasets library!