@NVIDIAAI
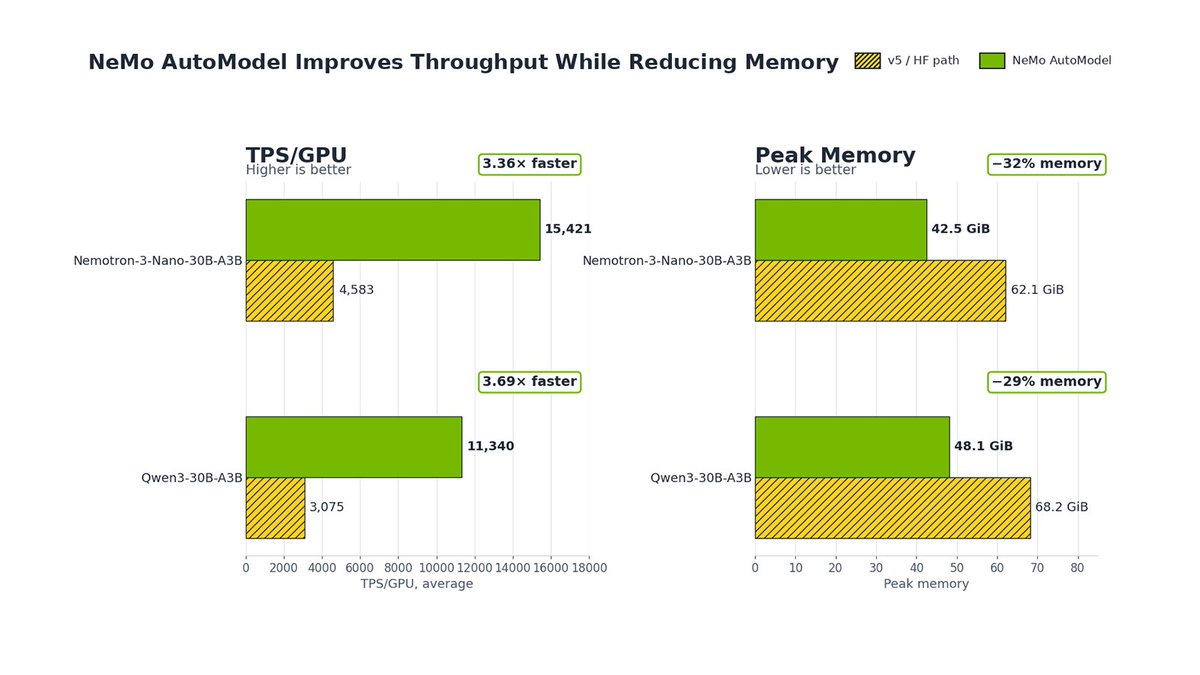
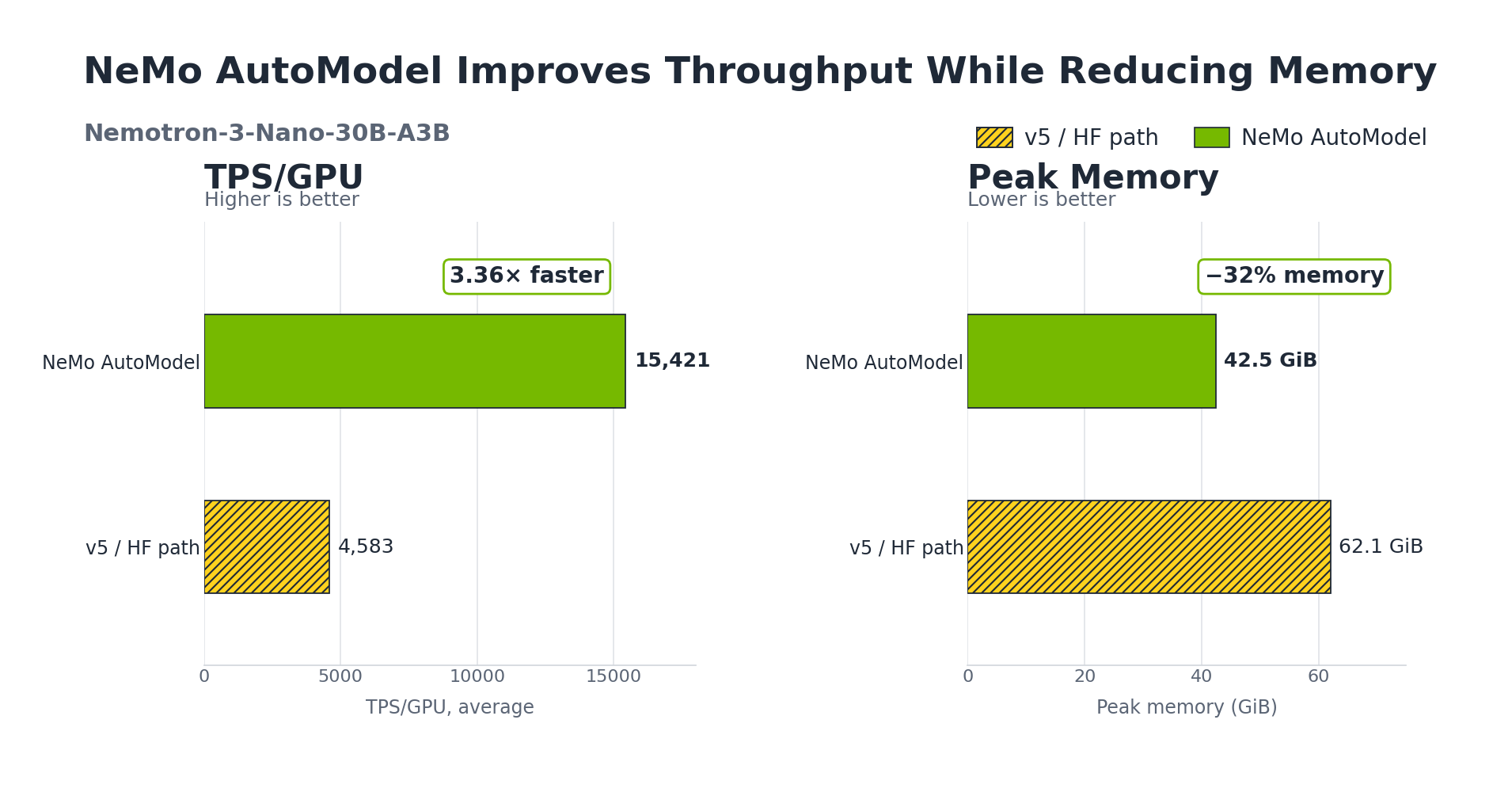
The rise of MoE models introduced new challenges in training, and @huggingface's Transformers v5 brought first-class support for solving them. Now, NeMo AutoModel builds on top of v5. Part of the NeMo framework for building models at scale, NeMo AutoModel brings optimizations to a broad set of model families through support for Expert Parallelism, DeepEP, and TransformerEngine kernels with a few lines of code. We found NeMo AutoModel brings a 3.4 to 3.7x higher training throughput for popular MoE models. You can read more here: https://t.co/TNlBsKWwrJ