@llama_index
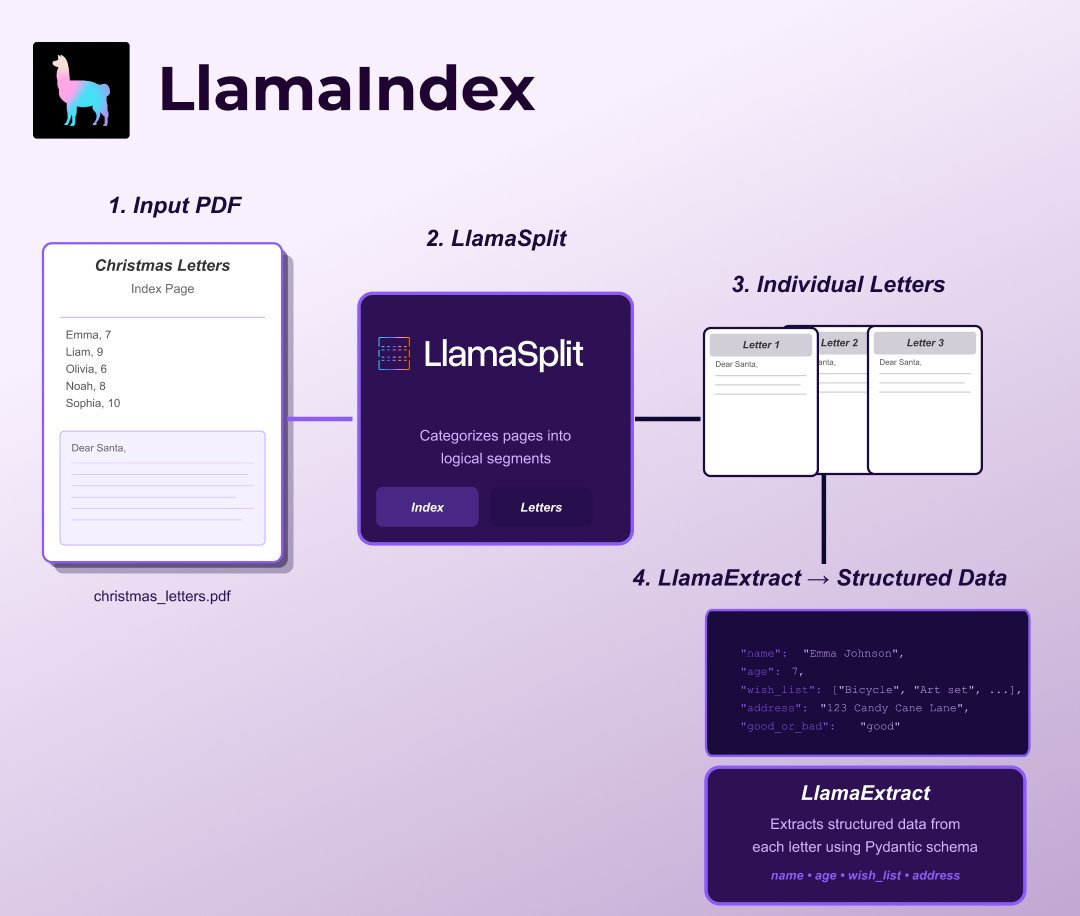
Santa receives thousands of letters every year—Processing these manually takes a lot of time, so this year, we're helping him out 👇 We built an agent to automate extracting wish-list items from letters 🎅 📤 Upload to LlamaCloud ✂️ LlamaSplit categorizes pages into logical segments (letters vs. index pages) using AI-powered document understanding 📋 LlamaExtract extracts structured data from each child's letter—name, age, wishlist items, address, and whether they've been good or bad (using Pydantic schemas for type-safe extraction) 🔄 LlamaAgent Workflows orchestrates the process with a fan-in pattern: split the document into segments, then extract data from each letter segment in parallel The result? Transform a messy multi-page PDF into clean, structured JSON for every child's wishlist—automatically handling document segmentation, parallel extraction, and data validation. Try it yourself in this Colab notebook: https://t.co/TbLLah1BV5