@CaimingXiong
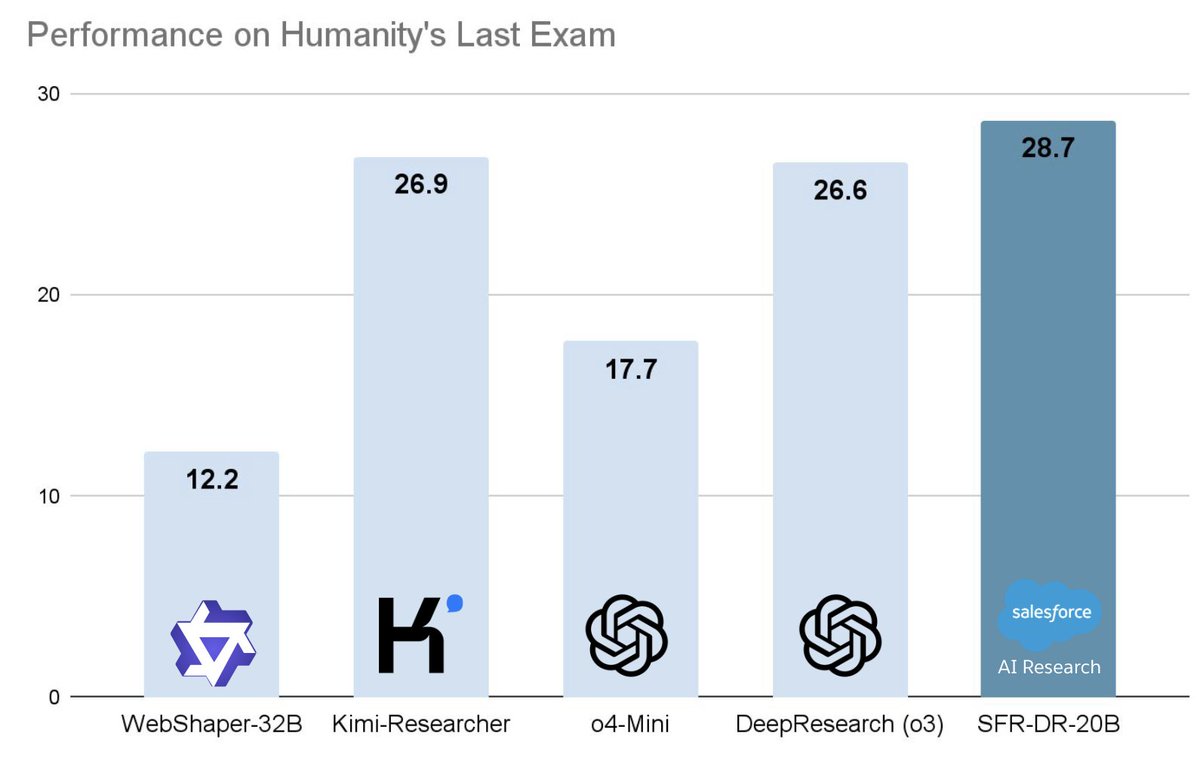
Meet SFR-DeepResearch (SFR-DR) 🤖: our RL-trained autonomous agents that can reason, search, and code their way through deep research tasks. 🚀SFR-DR-20B achieves 28.7% on Humanity's Last Exam (text-only) using only web search 🔍, browsing 🌐, and Python interpreter 🐍, surpassing DeepResearch with OpenAI o3 and Kimi Researcher. 🤖SFR-DR agents are trained to operate independently, without pre-defined multi-agent workflows. They autonomously plan, reason, and propose and take actions as defined by their tools. 🔄SFR-DR agents are trained with end-to-end RL. Starting from reasoning optimized models, our RL pipeline carefully preserves reasoning abilities while training models to become more capable research agents. 📝SFR-DR agents are also trained to manage their own memory by summarizing previous results when context becomes limited. This enables a virtually unlimited context window, enabling long-horizon tasks Paper: https://t.co/32idhdknhh #AIAgents #ReinforcementLearning #DeepResearch