@yifannnwu
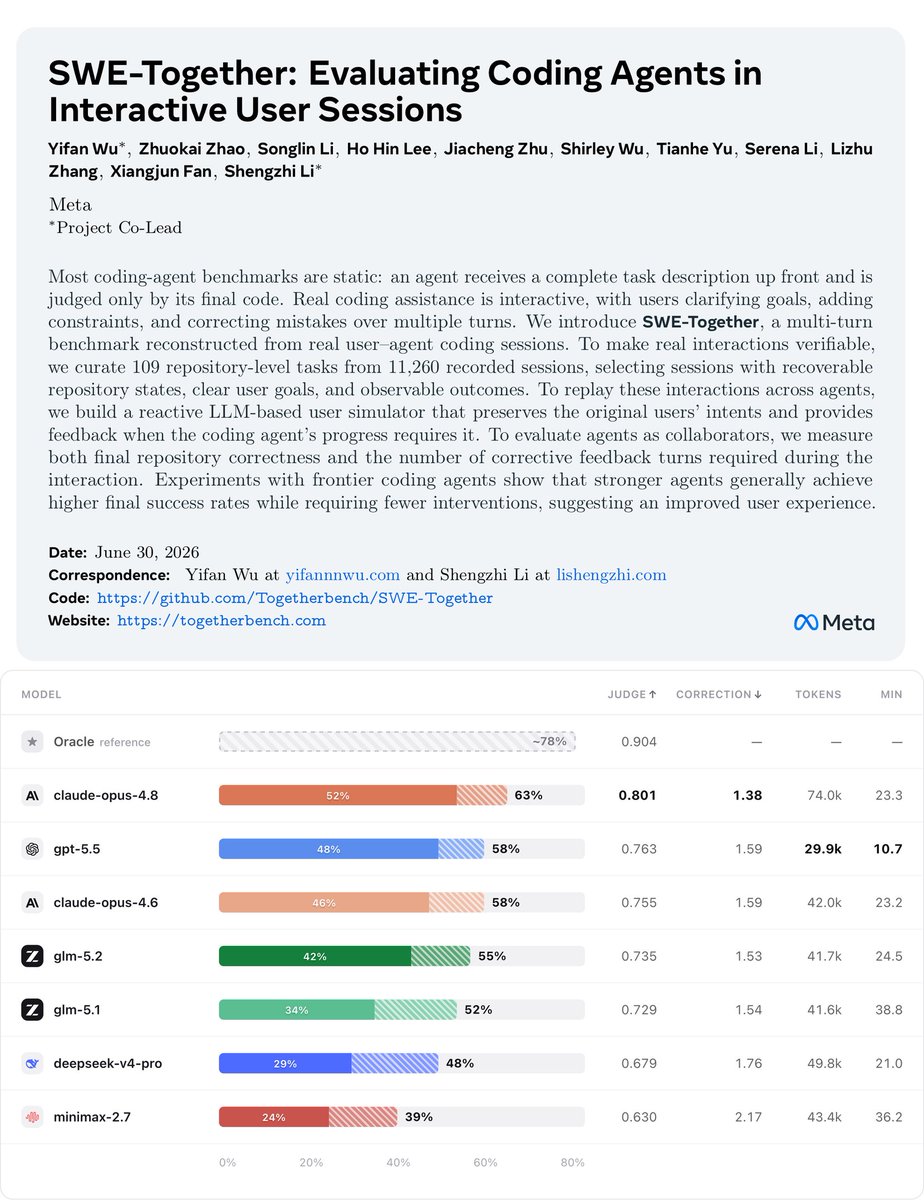
Introducing SWE-Together: a multi-turn benchmark built from real user–agent coding sessions. Coding agents are often benchmarked like exam-takers: given the full spec up front, then graded on the final code. But real coding help is a conversation — users clarify goals, add constraints, and correct course along the way. SWE-Together turns real coding work into a reproducible, verifiable benchmark: 109 repo-level tasks curated from 11,260 recorded sessions, replayed with a reactive LLM user simulator that preserves the original user’s intent. We evaluate agents as collaborators, not just patch generators: final pass rate and how many user interventions were needed to get there. In this evaluation snapshot, claude-opus-4.8 currently leads among the 7 agents we tested — achieving the highest pass rate while requiring the fewest user interventions. 📄 Paper: https://t.co/Zp5BSPpLTJ 💻 Code: https://t.co/NPgxCMLdHi 🌐 Website: https://t.co/BK50zRGReE