@winglian
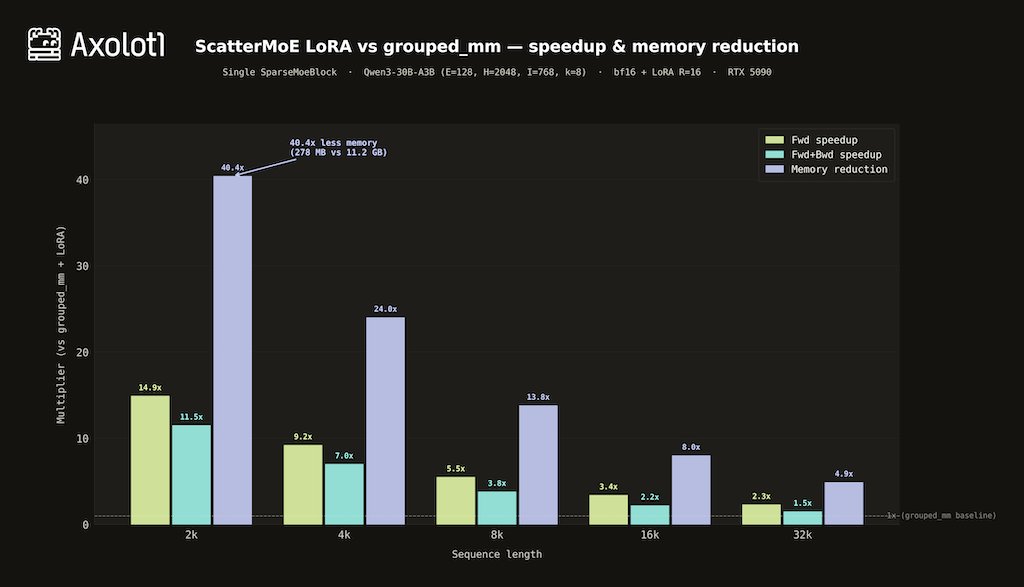
We built fused Triton kernels on top of @tanshawn's ScatterMoE — base expert matmul + LoRA in a single kernel pass. On Qwen3-30B-A3B (RTX 5090): - 14.9x faster forward at 2k ctx - 11.5x faster fwd+bwd - 40x less activation memory (278 MB vs 11.2 GB) Atomic-free backward kernels, autotunable tile sizes, NF4 selective dequant, and H200/B200 register pressure tuning. Works with @MistralAI MoEs, Qwen3, Qwen3.5, and @allen_ai OLMoE out of the box.