@chenru_duan
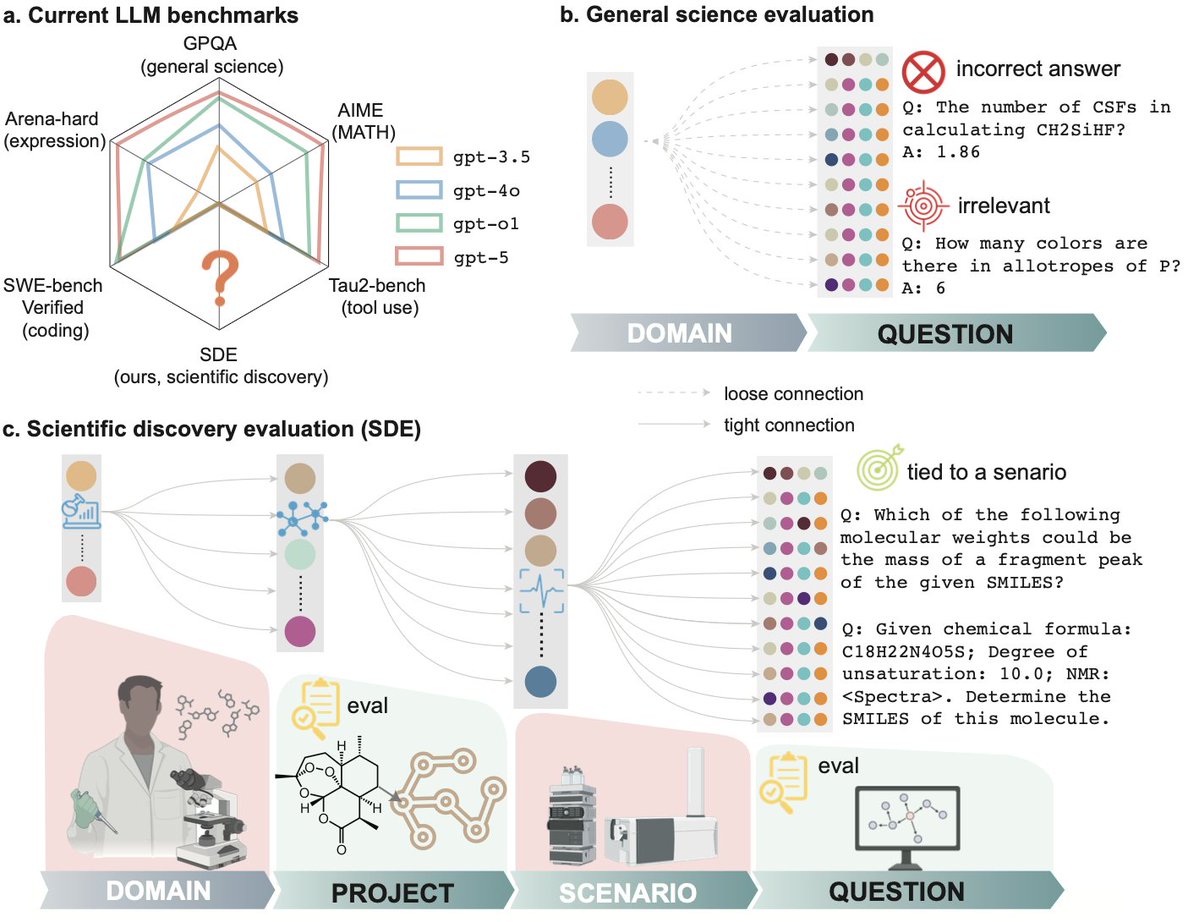
Is LLM ready for real scientific discovery? To find out, we gathered 50+ scientists from 20+ institutions establishing a multi-level evaluation framework: Not only on questions, but also on research scenarios and projects Current science benchmarks (like GPQA and MMMU) ask AI to answer quizzes. But science isn't a quiz. It’s an iterative loop of hypothesis, experiment, and analysis. Mastery of static, decontextualized questions, even if perfect, does not guarantee readiness to discovery, just as earning straight A’s in coursework does not indicate a great researcher. Today, we introduce Scientific Discovery Evaluation (SDE): A benchmark grounded in real-world research projects. There, research projects are decomposed into modular research scenarios from which vetted questions are sampled. LLMs are evaluated on 1. Question-level: targeted, expert-written problems embedded in real research scenarios (elucidating structure from NMR, forward reaction prediction, etc.), NOT sub-domains (analytical chemistry, inorganic materials, etc.) 2. Project-level: realistic scientific discovery loops (e.g., molecular design, materials discovery, protein engineering) where models must iteratively propose, test, and refine hypotheses. With a joint force of 50+ scientists from 20+ institutes, we gathered 8 projects, 43 research scenarios, and 1125 questions. Evaluation on these multiple levels reveals where current models succeed, where they fail, and why. It is of great joy to work with a 50+ author team in my first time of life - Thanks to you all for making it happen. @hello_jocelynlu, @YuanqiD, @BotaoYu24, @HowieH36226, @rogerluorl18, @YuanhaoQ, @YinkaiW, @Haorui_Wang123, @JeffGuo__, @SherryLixueC, @MengdiWang10, @lecong, @ParshinShojaee @KexinHuang5 @chandankreddy, @realadityanandy, @pschwllr, @KulikGroup, @hhsun1, @MoosaviSMohamad, and many others who are not in the x-universe. Also it’s exciting to see a concurrent release from @OpenAI on FrontierScience yesterday (@MilesKWang)! Their findings on the need for harder, expert-vetted evals, especially the huge performance gap between Olympiad and research questions, echo ours. SDE takes this a step further by moving beyond expert-level Q&A to explicitly evaluate the end-to-end discovery loop with project-level execution, where more finer-grained observations are thereby made possible. Core Findings Below: