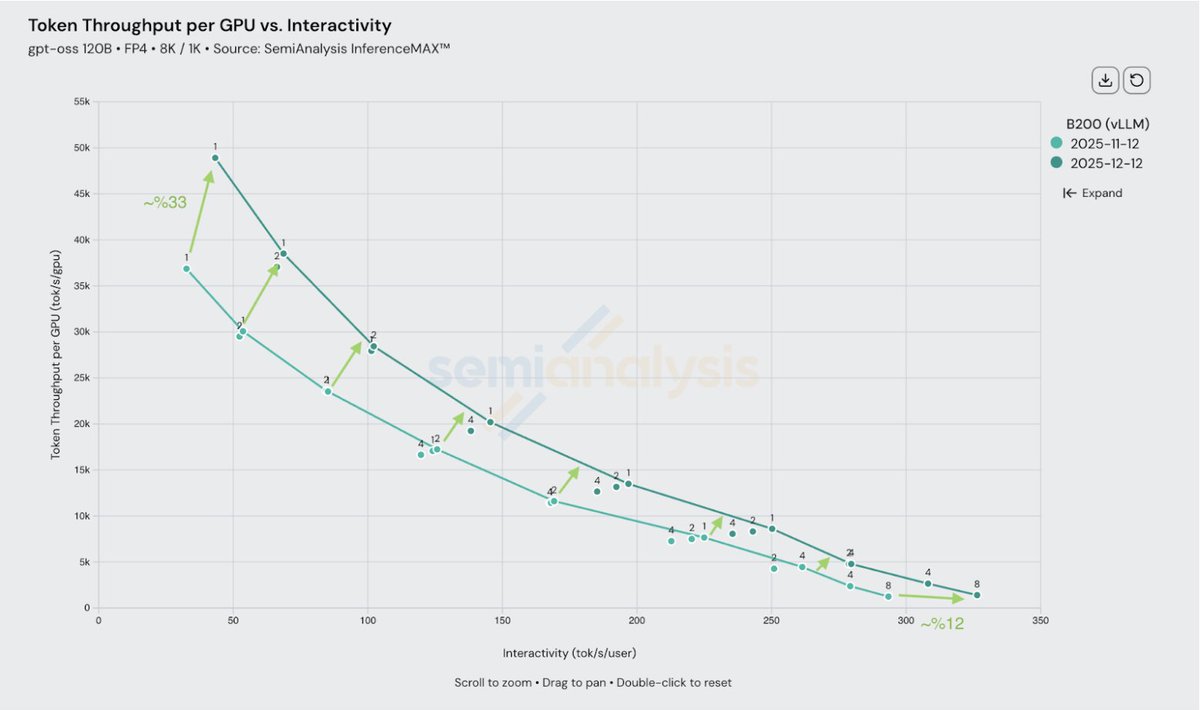
@vllm_project
vLLM delivers even more inference performance with the same GPU platform. In just 1 month, we've worked with NVIDIA to increase @nvidia Blackwell maximum throughput per GPU by up to 33% -- significantly reducing cost per token -- while also enabling even higher peak speed for the most latency-sensitive use cases powered by deep PyTorch integration and collaboration.