@jerryjliu0
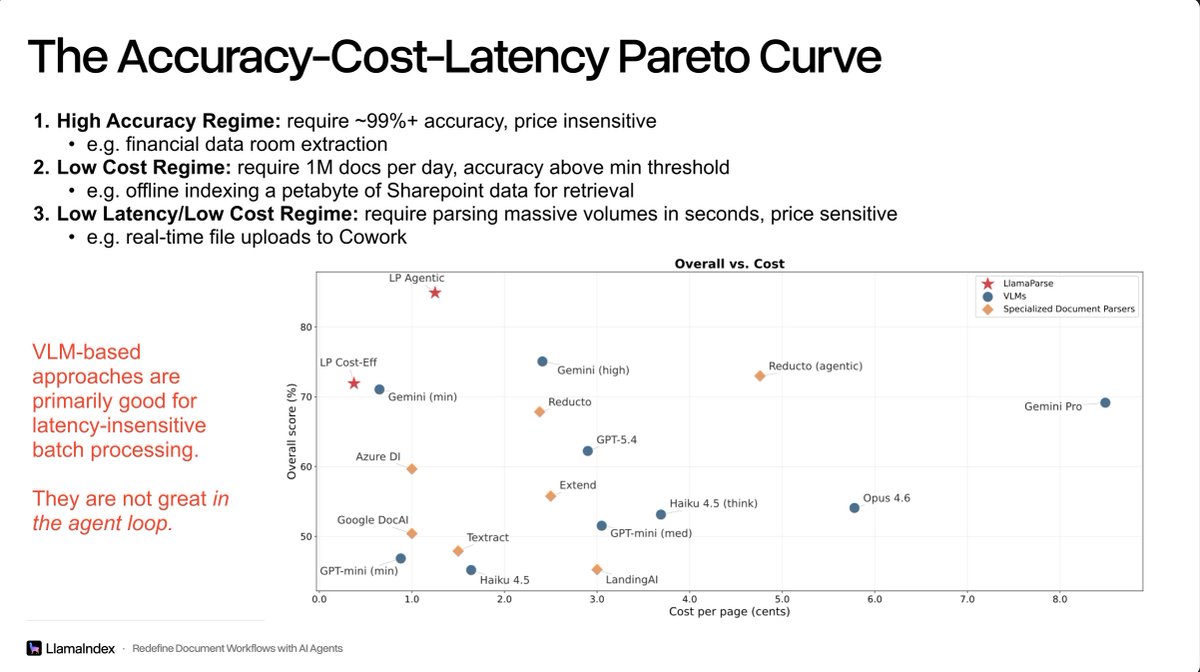
Fully solving document parsing includes covering every point on the Pareto curve of accuracy, cost, and latency: 1️⃣ High-accuracy parsing - requires 99%+ accuracy, price insensitive. Especially relevant in regulated industries like financial service and insurance. 2️⃣ Low cost, high volume parsing - requires inhaling a massive volume of documents as context for agents. Can run offline in a batch setting. 3️⃣Low latency and low cost parsing - these are use cases where the user is uploading a massive volume of files ad-hoc and in the agent loop (e.g. uploading 1k pdfs to claude cowork). Requires an extremely fast pass to make sense of the docs before a deeper dive LlamaParse covers the cost-accuracy modes for document OCR with our document agent harness. LiteParse, our OSS project, is designed to be in the agent loop, and can route to deeper VLM-enabled modes. I talked about this and other topics during the @aiDotEngineer talk today. Stay tuned for the slides! In the meantime, check out our full set of parsing results on ParseBench: https://t.co/PWczfhp0OX LlamaParse: https://t.co/XYZmx5TFz8 LiteParse: https://t.co/JNER0mVcB8