@weights_biases
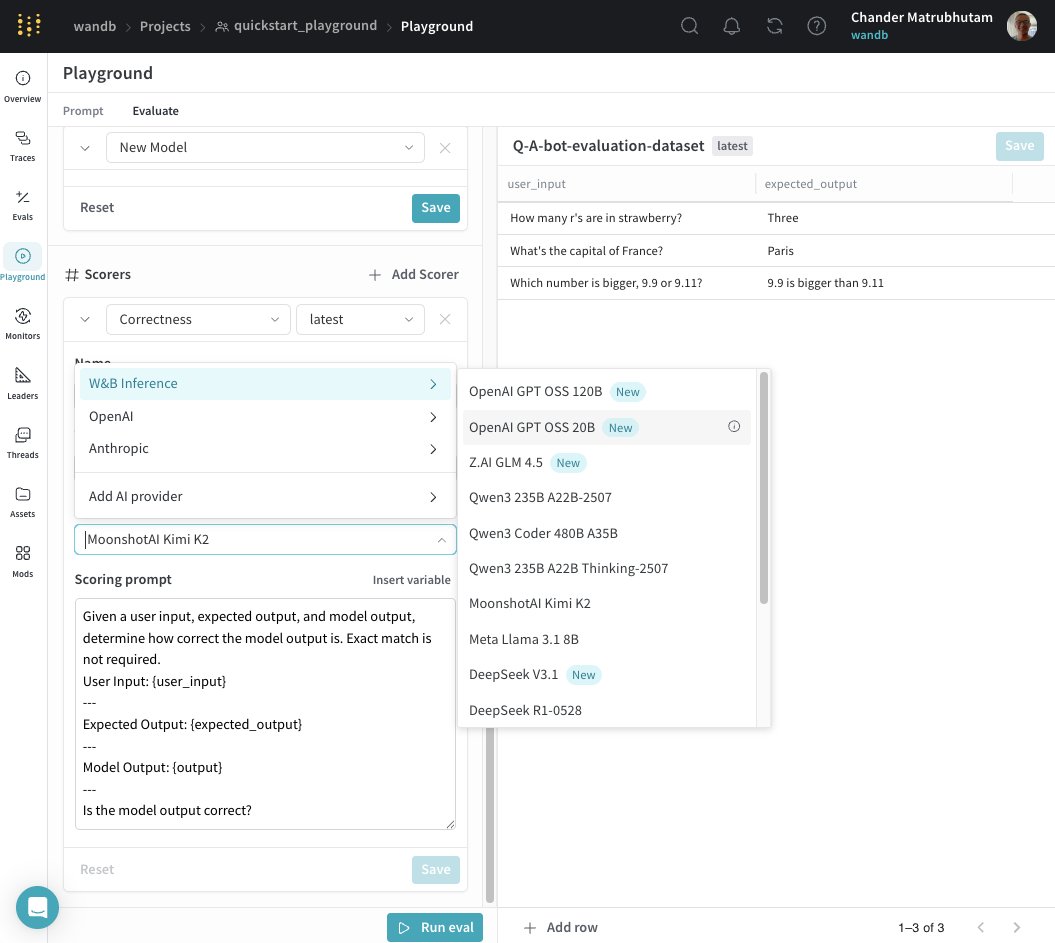
Evaluating LLMs in @weave_wb just got a whole lot easier! Now you can run your evals right in the UI, without writing a single line of code. Select datasets, pick models, include LLM-as-judge scorers, and hit Run. Simple as that. https://t.co/vfZLFyivTf