@ModelScope2022
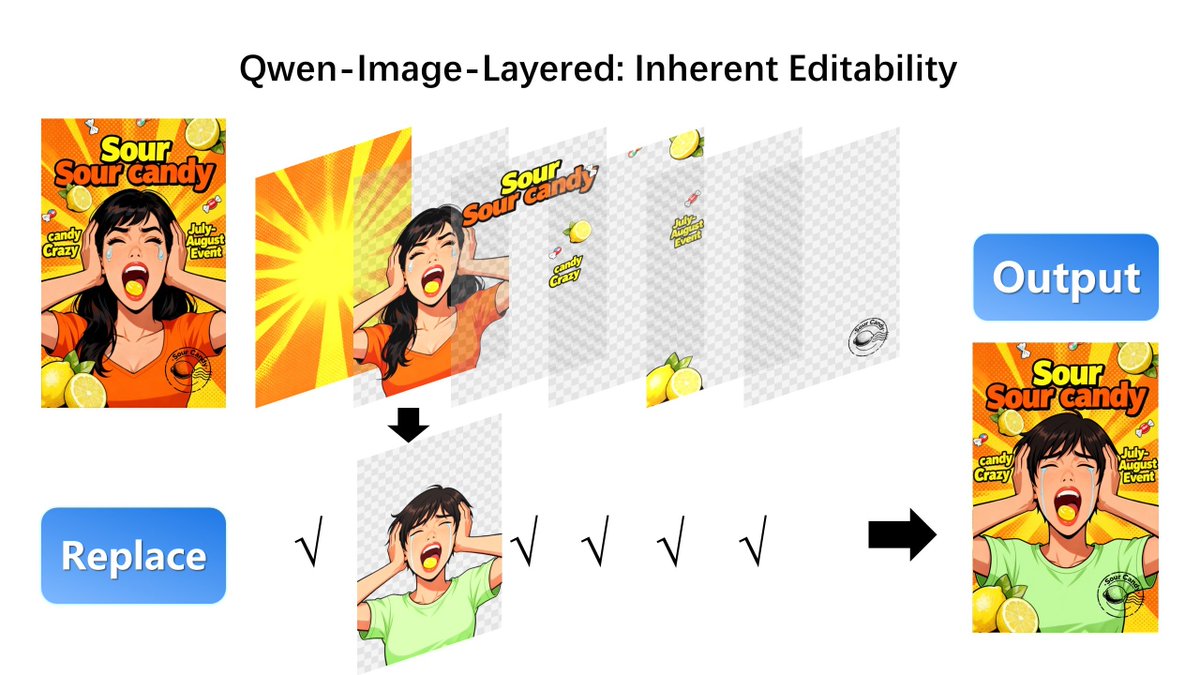
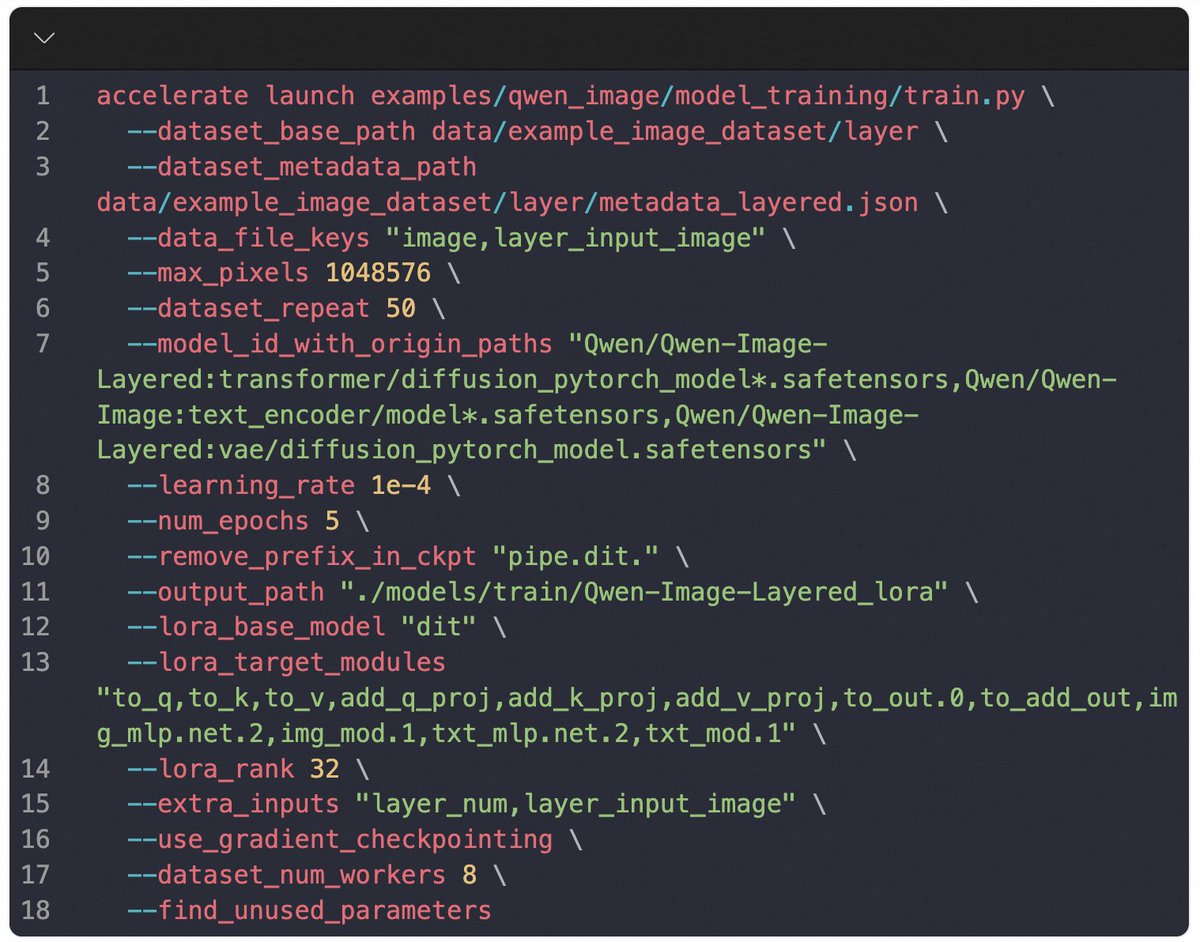
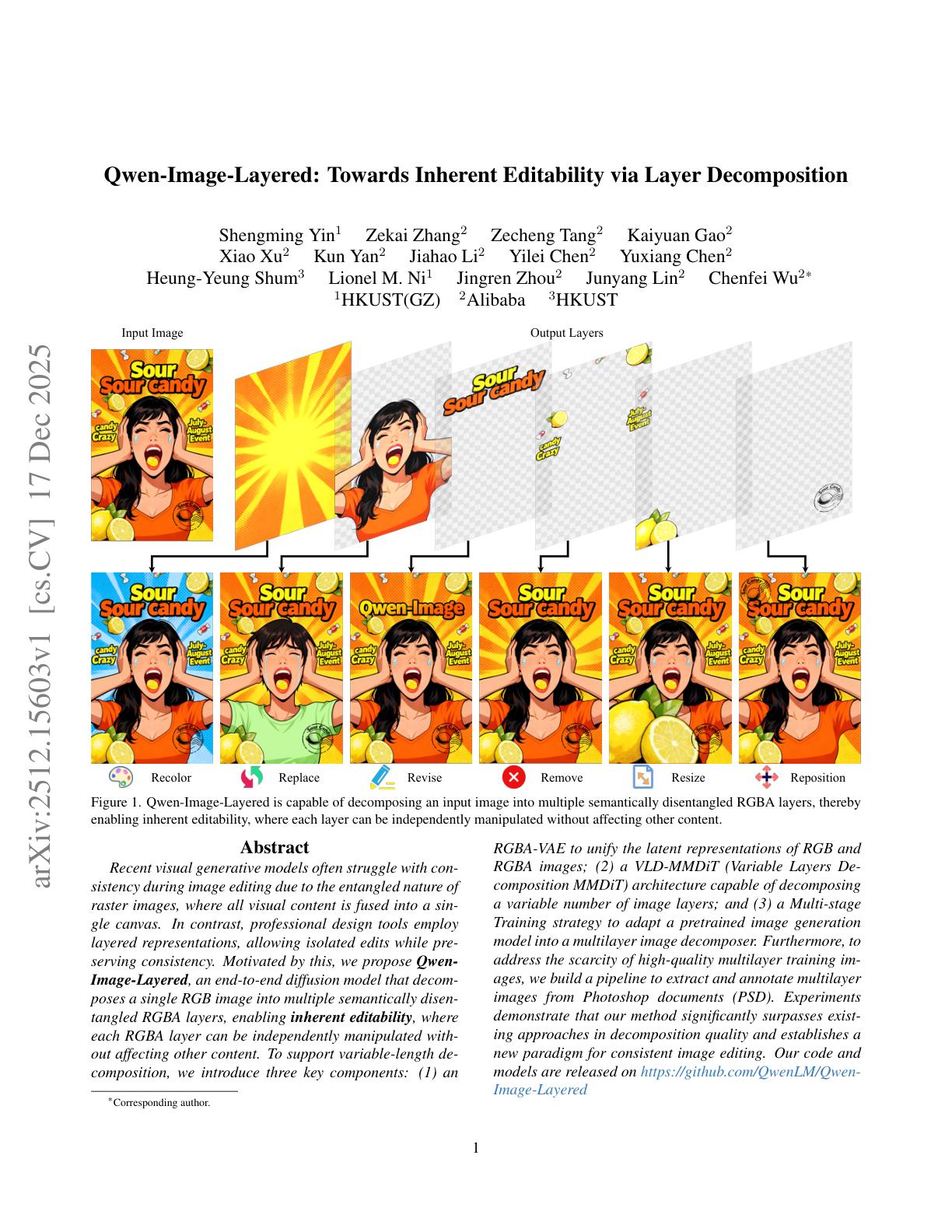
🚀DiffSynth-Studio now supports Qwen-Image-Layered training—so you can train your own layered image decomposer with just a few lines of code. 🛠️ Think Photoshop for AI images: move, recolor, or replace one element—background stays crisp, style stays intact. 🎨 Qwen-Image-Layered decomposes any RGB image into semantic RGBA layers, enabling true inherent editability: ✅ Reposition a person → background untouched ✅ Resize text → no style drift ✅ Swap a shirt → face unchanged Powered by RGBA-VAE + VLD-MMDiT, it supports variable layers and recursive decomposition—no ghosting, no artifacts. Train your own model today with DiffSynth-Studio! 🔗 DiffSynth-Stuido:https://t.co/CViCA6Xh2s 🤖 Model: https://t.co/V9yXltIX9N 🌟 Demo: https://t.co/ySdRT6dEpi 📄 Paper: https://t.co/5fsAfPLcqz