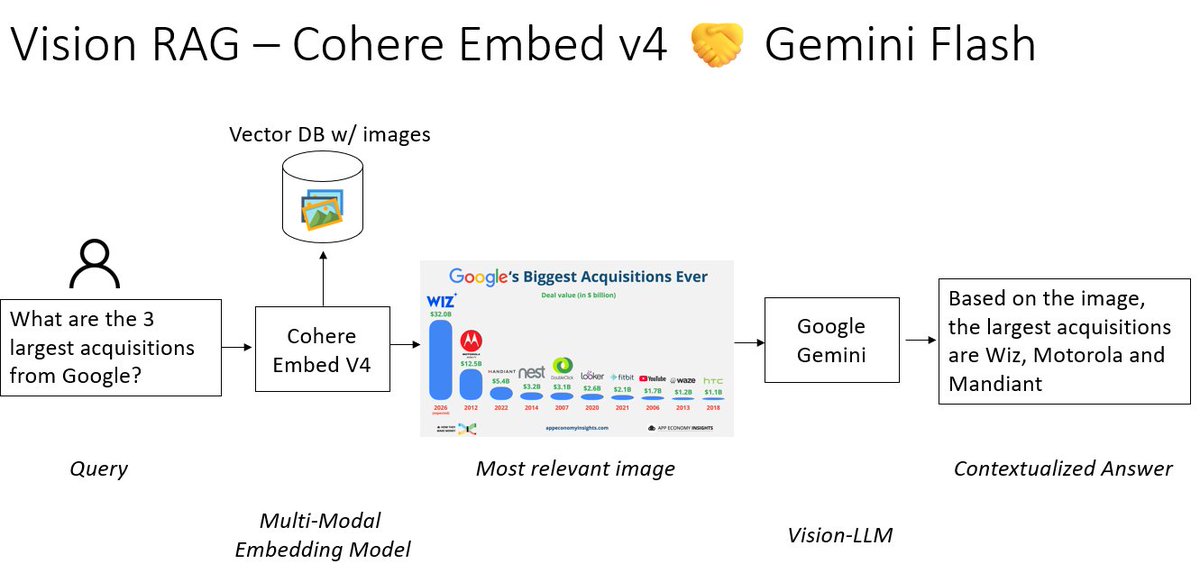
@Nils_Reimers
𝐕𝐢𝐬𝐢𝐨𝐧 𝐑𝐀𝐆𝐑𝐀𝐆 𝐨𝐧 𝐂𝐨𝐦𝐩𝐥𝐞𝐱 𝐆𝐫𝐚𝐩𝐡𝐢𝐜𝐬🖼️ RAG is mostly text-only, even though we have so much data available as charts/figures. Combine @cohere lastest Embed v4 embedding model with a vision-LLM like @GoogleDeepMind Gemini to get 𝐕𝐢𝐬𝐢𝐨𝐧 𝐑𝐀𝐆 https://t.co/wEwOYv3giW