@seb_ruder
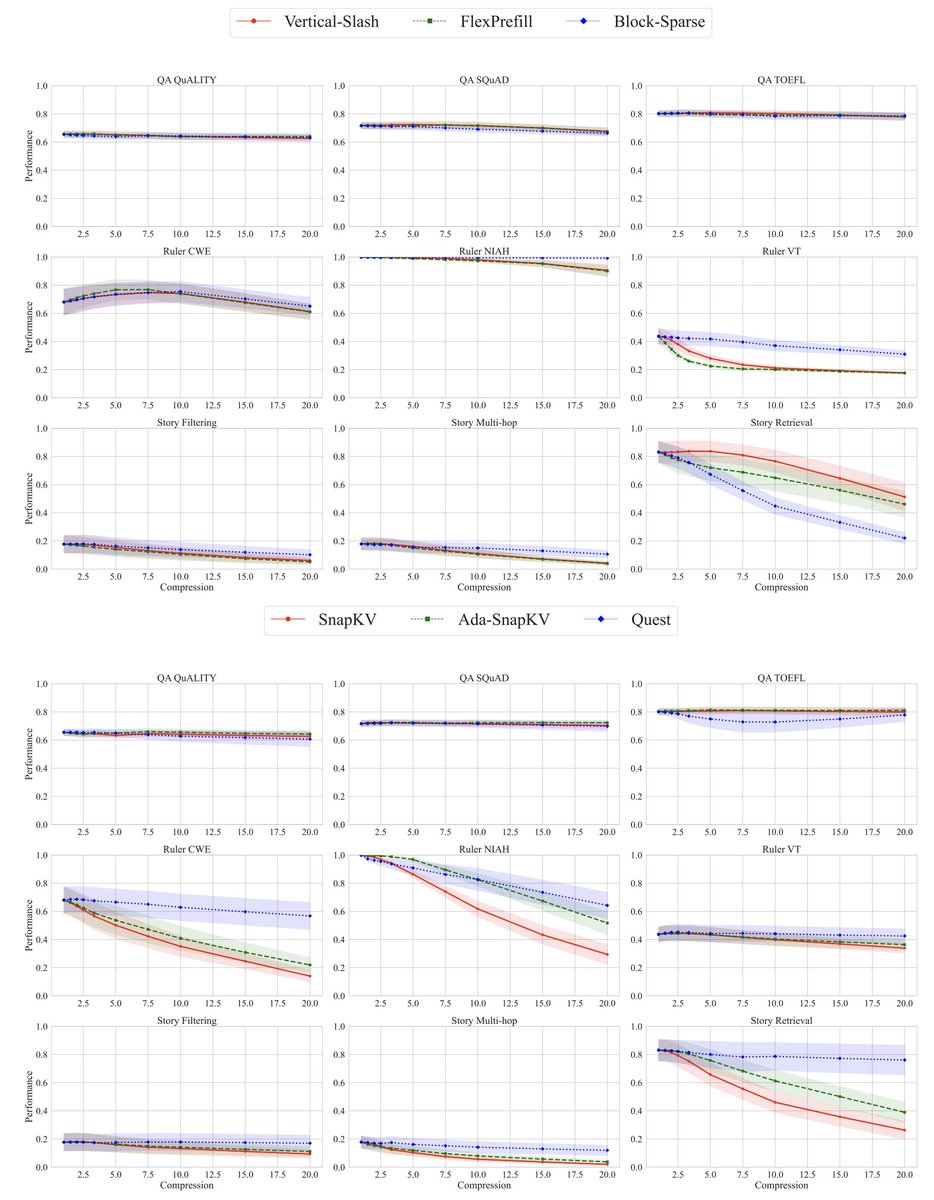
Our findings: 1) For short seqs, increasing density or size provides gains. For long seqs, high sparsity performs best. 2) Higher sparsity is possible for decoding and larger models. However, most configs deteriorate performance significantly for at least one task. 3) There is no single sparse attention method that excels across all tasks. 4) We establish scaling laws based on model size, sequence length, compression ratio, and task id that reliably predict performance.