@github
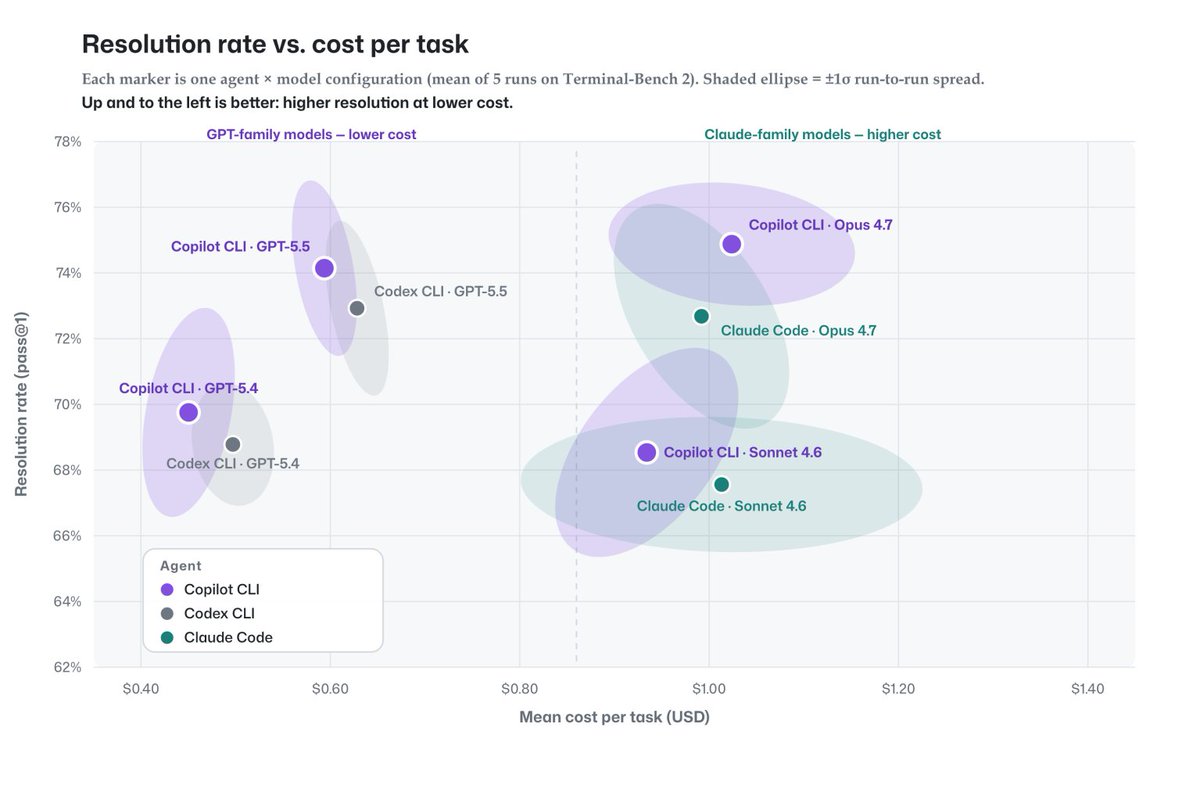
We benchmarked the GitHub Copilot agentic harness against the harnesses that ship leading models natively. Holding the model and task fixed across SWE-bench Verified, SWE-bench Pro, SkillsBench, TerminalBench, and Win-Hill, the results were clear: ✅ Task resolution on par with model-vendor harnesses ✅ Fewer tokens across most configurations 💡 A key learning: With GitHub Copilot supporting more than 20 models, you're free to pick efficiency or peak quality per task.