@jiqizhixin
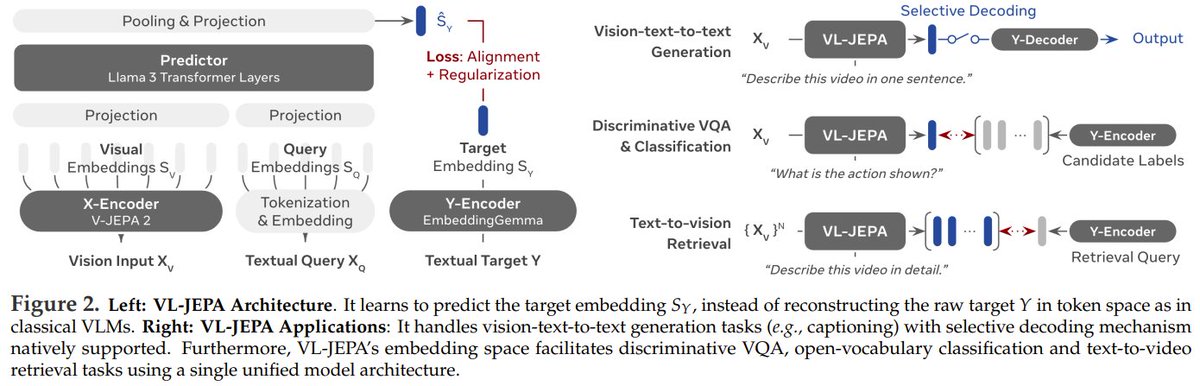
LeCun's JEPA has evolved into a vision-language model, with 1.6B parameters rivaling the 72B Qwen-VL. Instead of predicting words directly, the proposed VL-JEPA learns to predict the core "meaning" of a text in an abstract space, ignoring surface-level wording variations. This method outperforms standard token-based training with 50% fewer parameters. It beats models like CLIP & SigLIP2 on video classification/retrieval tasks and matches larger VLMs on VQA, while using a decoder only when needed to cut decoding ops by nearly 3x. VL-JEPA: Joint Embedding Predictive Architecture for Vision-language Paper: https://t.co/rGglBXvKex Our report: https://t.co/TXEHRquSBr