@llama_index
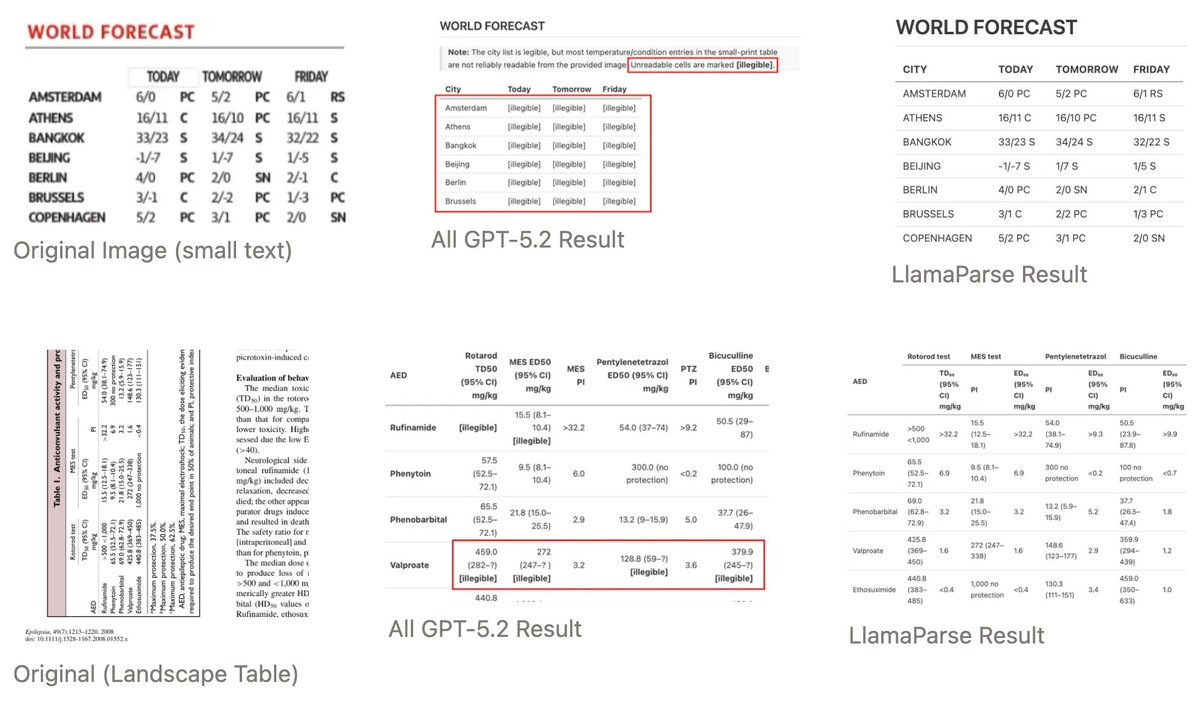
More reasoning doesn't always mean better results - especially for document parsing. We tested GPT-5.2 at four reasoning levels on complex documents and found that higher reasoning actually hurt performance while dramatically increasing costs and latency. 🧠 Reasoning models hallucinate content that isn't there, filling in "missing" table cells with inferred values 📊 They split single tables into multiple sections by overthinking structural boundaries ⚡ Processing time increased 5x with xHigh reasoning (241s vs 47s) while accuracy stayed flat at ~0.79 💰 Our LlamaParse Agentic outperformed all reasoning levels at 18x lower cost and 13x faster speed You can't reason past what you can't see. Vision encoders lose pixel-level information before reasoning even starts, and no amount of thinking tokens can recover that lost detail. Our solution uses a pipeline approach - specialized OCR extracts text at native resolution, then LLMs structure what's already been accurately read. Each component plays to its strengths instead of forcing one model to handle everything. Read the full analysis: https://t.co/gWDOpfHnWm