@gerardsans
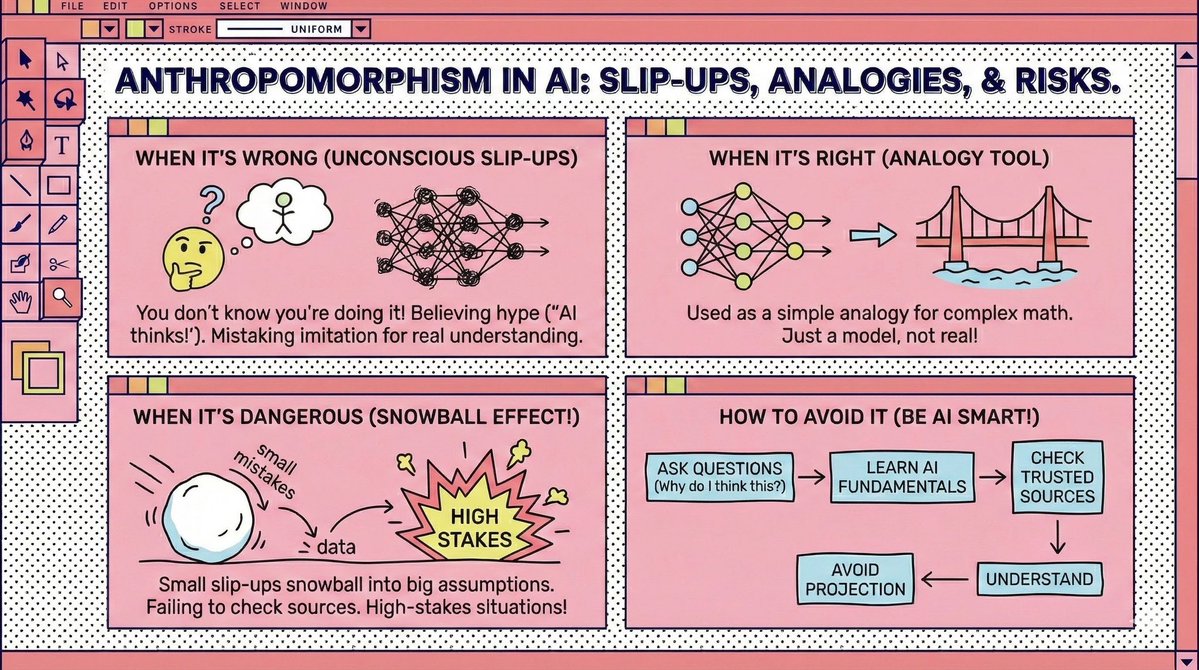
Bold Lacanian read on AI hallucination, but the analogy leans on heavy anthropomorphic baggage. All LLM outputs start the same: every token is just next token prediction. A continuation becomes a hallucination only when a human adds real world context the model never had. There is no psyche trying to fill a lack. Personality in LLMs is RLHF rewarding fluency, not truth. Apparent traits are prompt shaped data artefacts as in Han et al 2025 arXiv:2509.03730. Self reported Big Five maps to behaviour in about 24 percent of cases. This is a stochastic funnel, not a barred subject. The confidence in hallucinations is not Lacanian jouissance. It is the Eliza effect. We project coherence and intention, then blame the model for a mismatch created by our own projection. Great paper, but it needs a reminder to flag every anthropomorphic move with the actual technical context. Call out when you are interpreting output after the fact, not describing how it was produced, and avoid projecting human traits that do not exist. Follow for more insights or subscribe to receive updates in your inbox: https://t.co/DybOvoBDEw