@DAlistarh
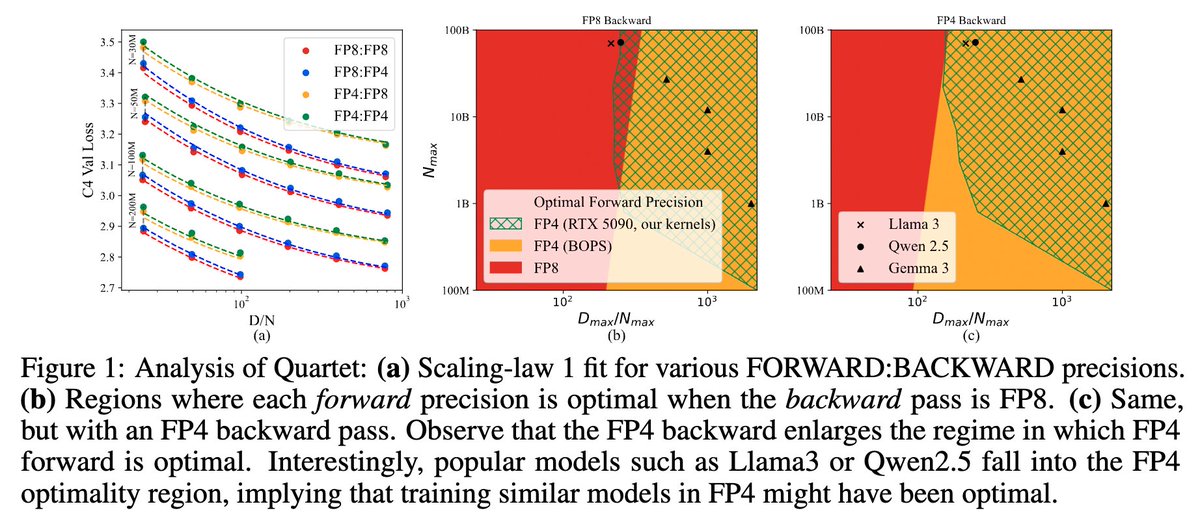
We are introducing Quartet, a fully FP4-native training method for Large Language Models, achieving optimal accuracy-efficiency trade-offs on NVIDIA Blackwell GPUs! Quartet can be used to train billion-scale models in FP4 faster than FP8 or FP16, at matching accuracy. [1/4] https://t.co/gggPqEgcPZ