@askalphaxiv
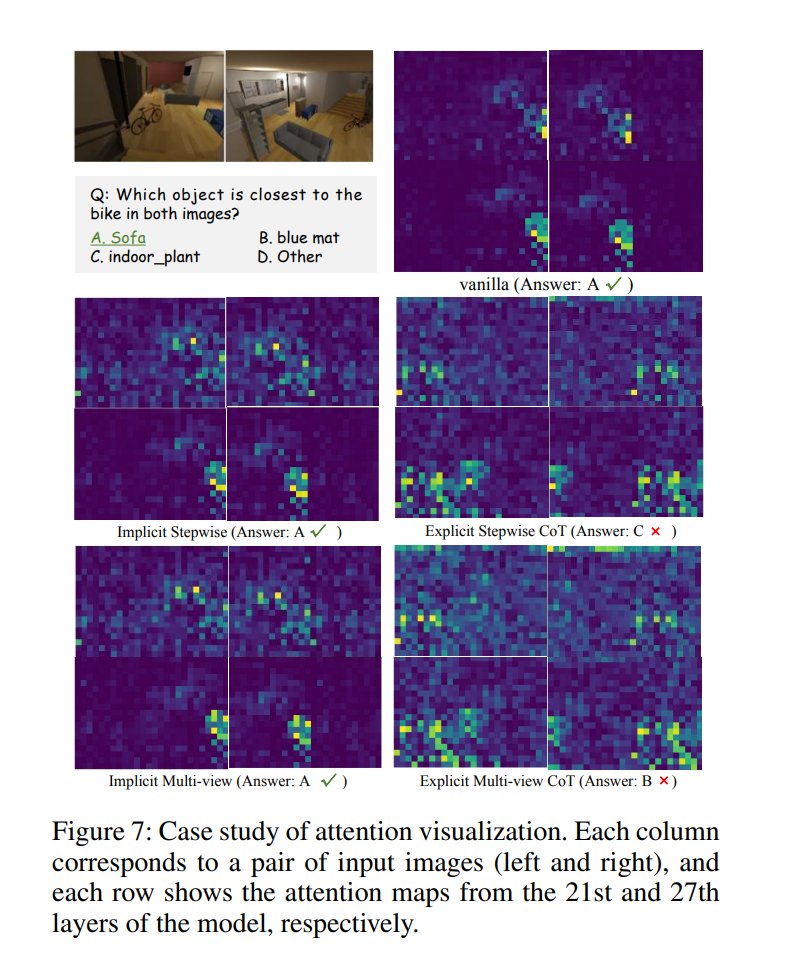
Why Do Multimodal LLMs (MLLM) Struggle with Spatial Understanding? This research shows that MLLMs’ spatial struggles aren’t from data scarcity, but from architecture. Spatial ability relies on the vision encoder’s positional cues, so a redesign like prompt targeting is needed. https://t.co/g0AL7aJOs2