@jcz42
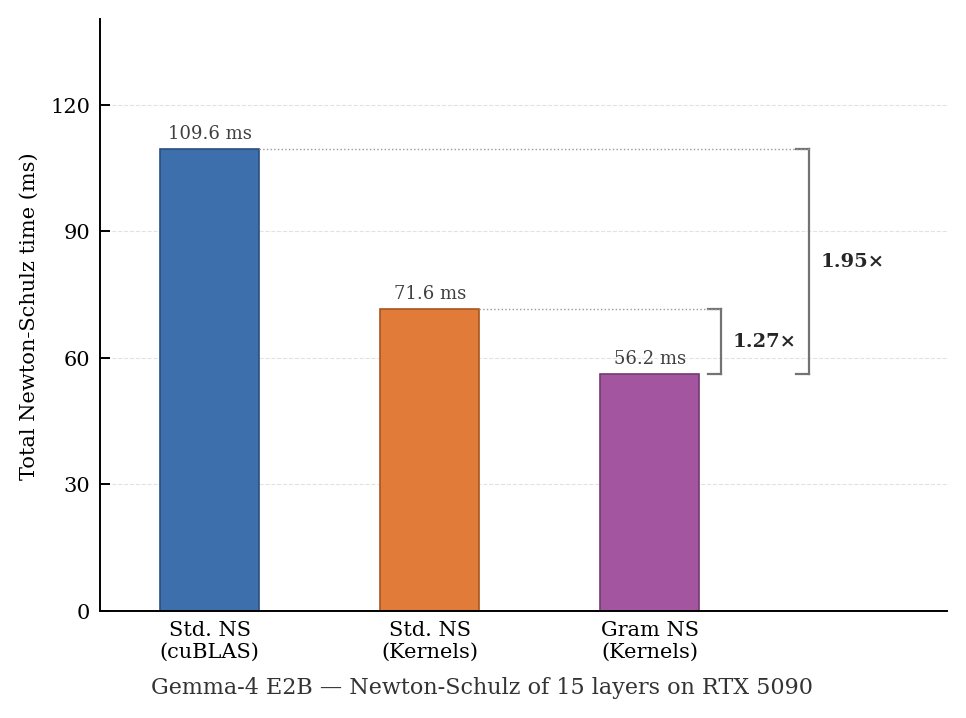
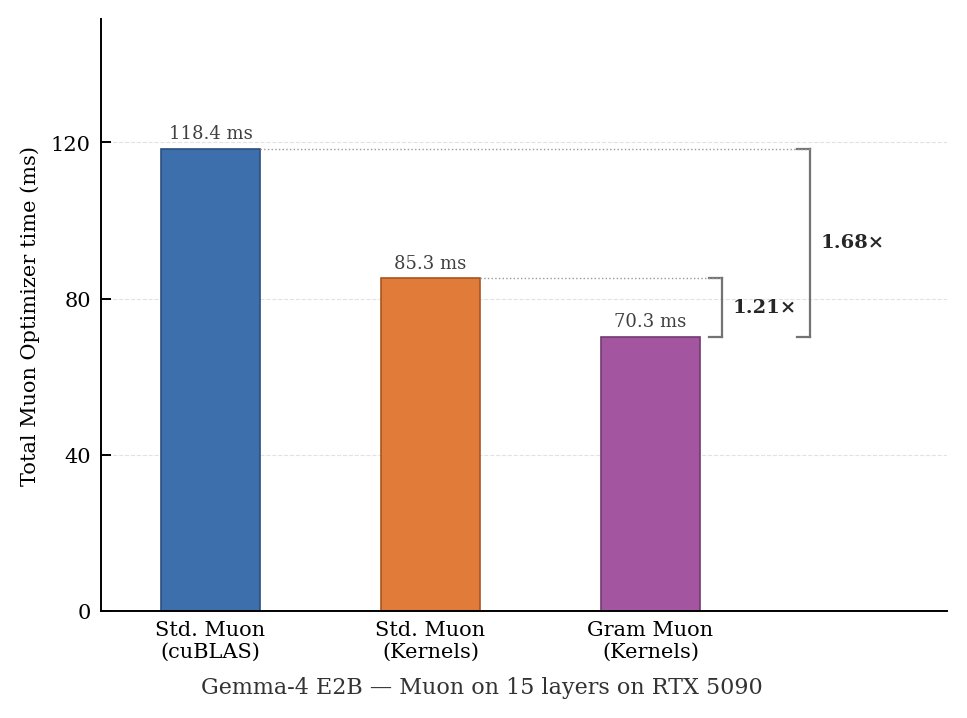
Gram Newton-Schulz’s CuTeDSL symmetric kernels now support Blackwell consumer cards like RTX 5090! This should be especially helpful for finetuning/RL on on-device models, where Muon’s Newton-Schulz routine occurs more frequently due to smaller batch sizes. We see 2x faster Newton-Schulz and 1.7x faster optimizer time on 15 layers of the recent Gemma-4 E2B model with Gram Newton-Schulz. Huge thanks to the open source contribution that enabled Blackwell consumer symmetric GEMM support in Quack (PR linked below) - we’re super excited to see interest in on-device Muon from the community (and hope that Quack's symmetric kernel abstraction is convenient to use 🙂)! Original work with @noahamsel @_berlinchen @tri_dao Code linked below: