@paperswithdata
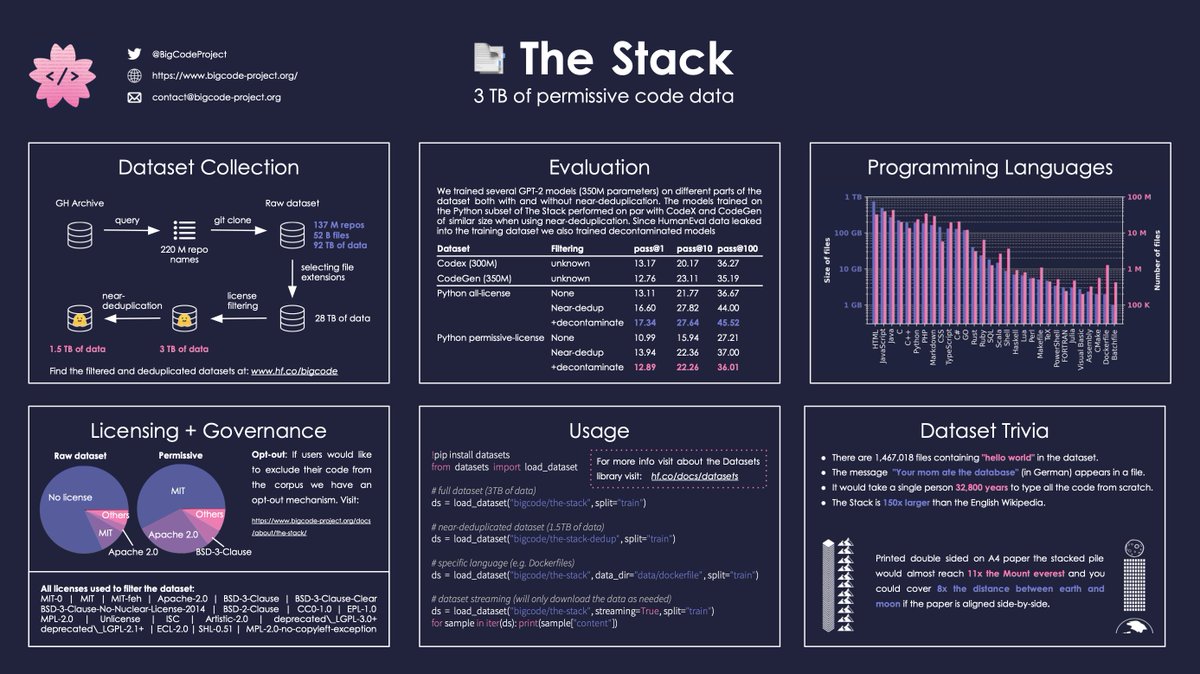
💻The Stack: a dataset for pre-training Code LLMs. It contains 3TB of permissively-licensed code in 30 programming languages. It’s created as part of the BigCode Project, an open scientific collaboration working on responsible development of Code LLMs. https://t.co/2zHTyCztBZ https://t.co/j9Z48PLFTM