@gerardsans
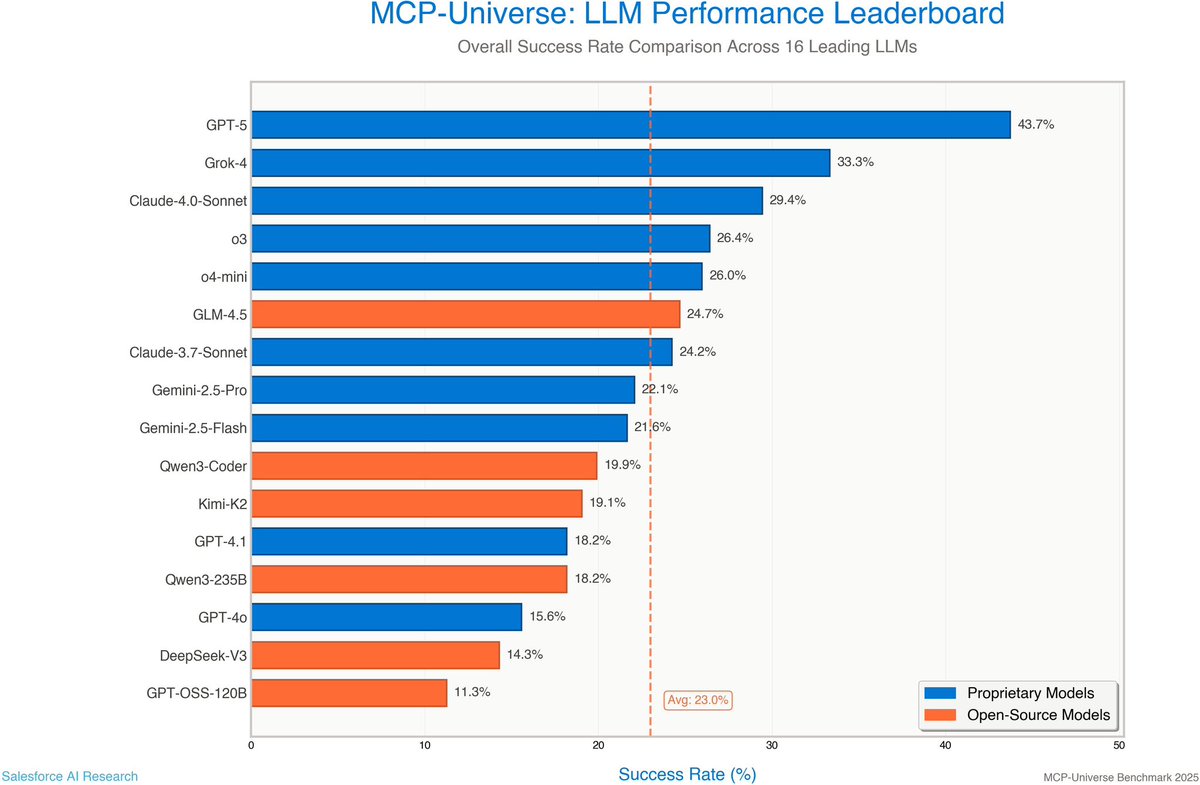
The raw truth: across 16 leading LLMs, AI agents succeed at fewer than 1 in 4 tasks. These tests use simple API calls, revealing a costly, fragile system prone to failure outside demo environments on current MCP servers. https://t.co/cIKr7BWGzT