@arankomatsuzaki
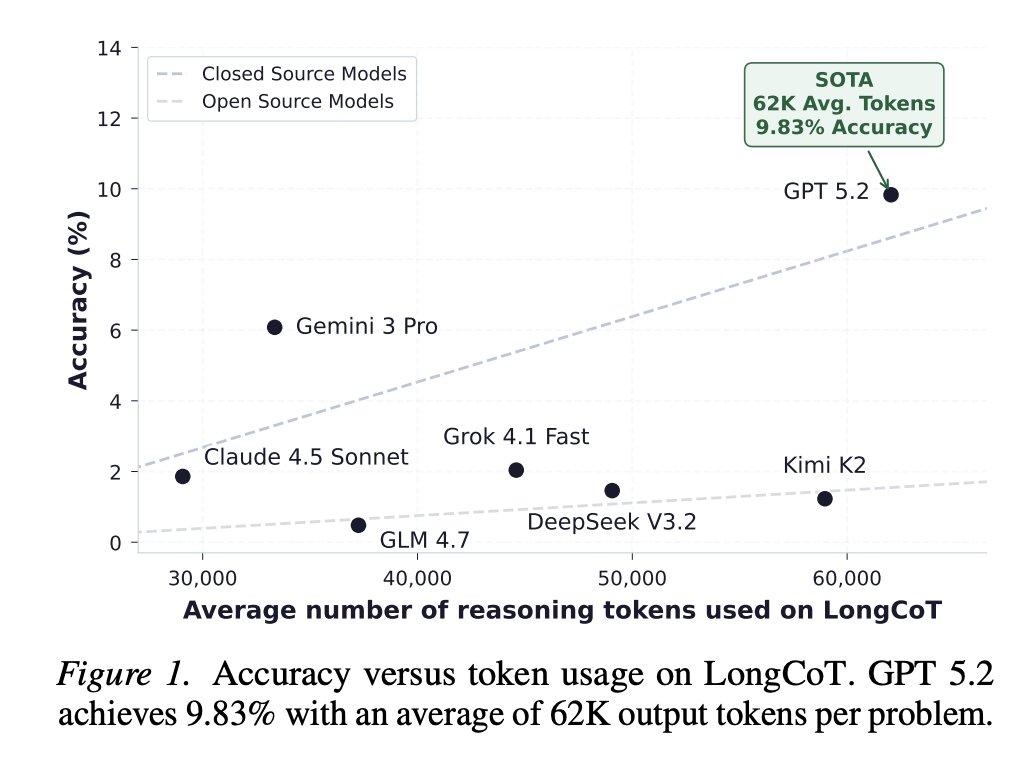
LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning - 2,500 expert-designed problems spanning science, chess, and logic that demand up to hundreds of thousands of reasoning tokens - The best models achieve <10% accuracy https://t.co/dHFroaryGW