Your curated collection of saved posts and media
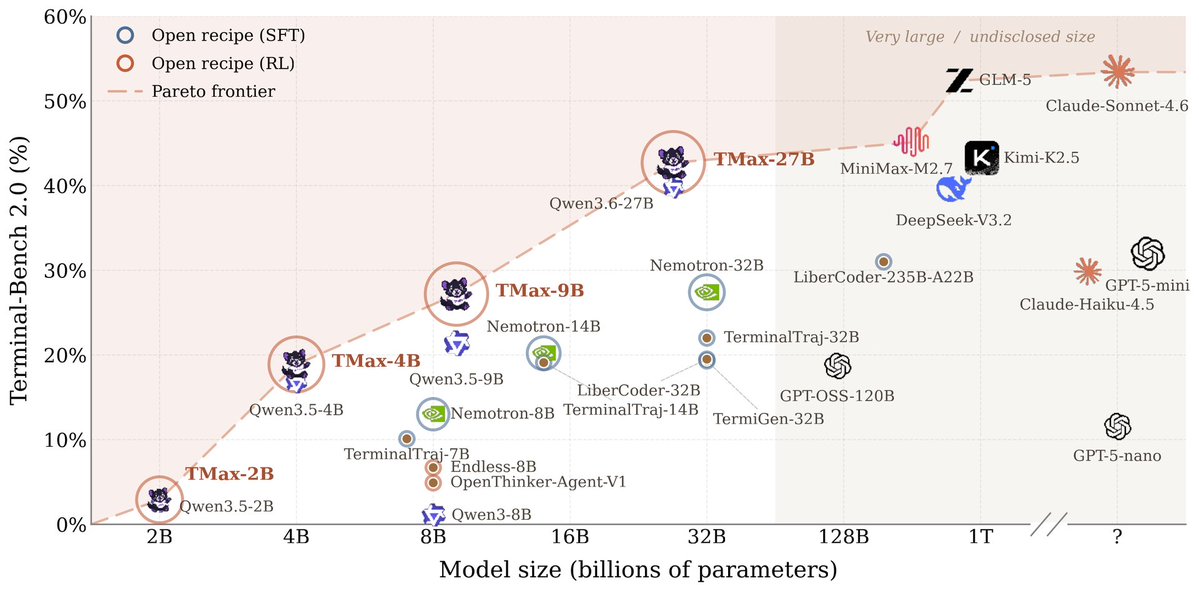
Ai2 just released their Qwen 3.5 9B terminal agent on Hugging Face Built with DPPO on the OpenThoughts dataset, it leads the TMax ablations with 53.0% on Terminal Bench Lite. https://t.co/E8PN1wB6fl
It's all open source in ART. If you're running GRPO-style RL with a heavy shared prompt, the speedup is right there. Give it a try. Blog: https://t.co/FafhwPgeVa @OpenPipeAI ART Github: https://t.co/SHx8iBxYNv


Explore the data ⬇️ https://t.co/OC0rDWWZQh

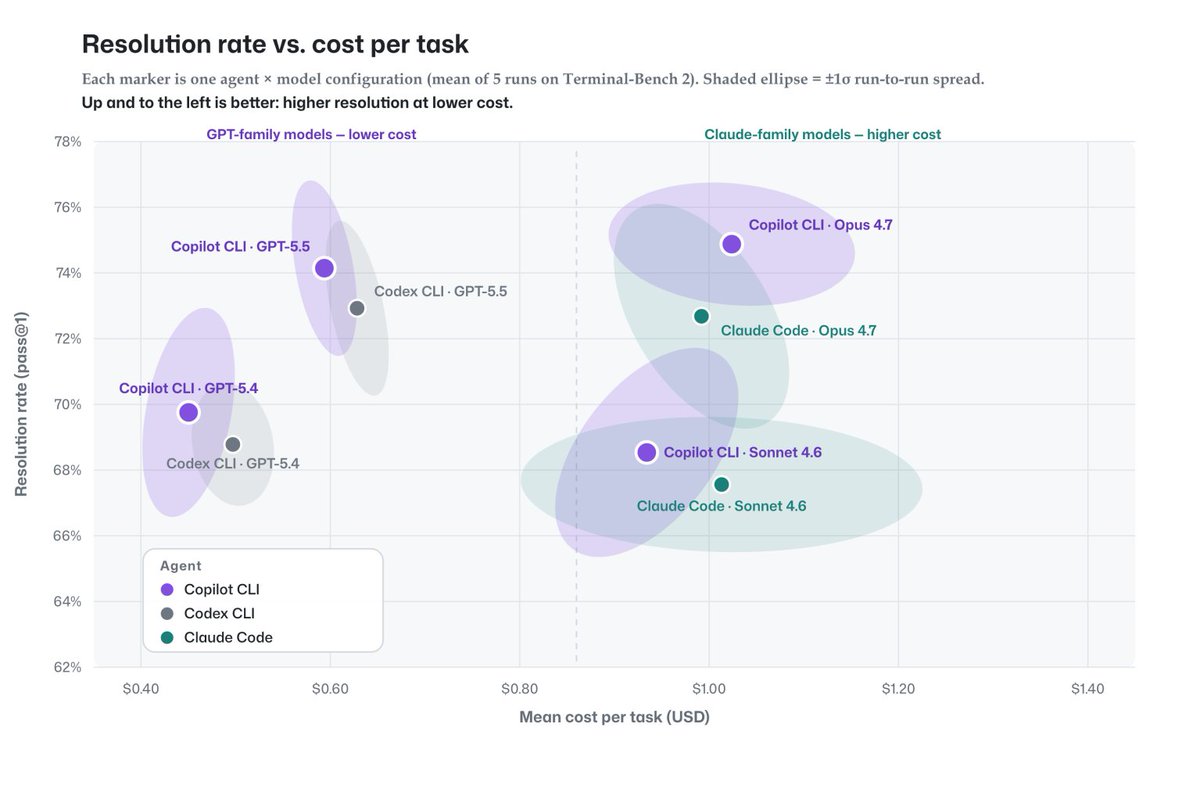
We benchmarked the GitHub Copilot agentic harness against the harnesses that ship leading models natively. Holding the model and task fixed across SWE-bench Verified, SWE-bench Pro, SkillsBench, TerminalBench, and Win-Hill, the results were clear: ✅ Task resolution on par with model-vendor harnesses ✅ Fewer tokens across most configurations 💡 A key learning: With GitHub Copilot supporting more than 20 models, you're free to pick efficiency or peak quality per task.
Frontier AI models are built from thousands of small decisions: data sourcing, filtering, mixtures, curricula, scaling experiments, optimizer choices, kernels, evals, failed runs, and protocols for deciding what gets scaled. This is process knowledge.
Great work to the Meta AI team! Best part of it is they have open-sourced the code and plan to open-source data too! So you should be able to train your own brain-to-text model, assuming you have your own MEG! 😄 code: https://t.co/XF9z4JCzzq
@wayama_ryousuke 🚨 TRINITY is sharp engineering. A 0.6B Qwen backbone, ~10k-param head reading penultimate hidden states, sep-CMA-ES tuning it to hand off between seven LLMs in a Thinker/Worker/Verifier loop. Token-efficient, benchmark-strong, and genuinely clever at test-time composition without touching weights. Credit where it's due. The science is where the story collapses. The "Plan/Act/Verify" loop is still pure textual puppetry. One model emits a plan, another emits steps, a third stochastic parrot emits ACCEPT or REVISE. No external verifier, no interpreter, no grounding in code execution or world state. Just more tokens judging more tokens until the turn budget expires. Stochastic parrots verifying stochastic parrots isn't reasoning. It's statistical mirror-gazing dressed as collaboration. The routing claim takes the same hit. Hidden-state space on these models is already cleanly separable by task label: SVM hits 100% on the obvious buckets. No hard intra-domain distinctions were stress-tested. What sep-CMA-ES actually did, across ~30k LLM calls and 60 iterations, was brute-force a high-dimensional lookup table for a decision surface a logistic regression on the same features would have found before lunch. No online learning, no policy gradient, no adaptation after the museum piece is frozen. The "evolution" is expensive offline calibration, not emergence. OpenRouter already routes dynamically and without the ceremony. Trinity demonstrates that heavy domain splitting plus brute-force coordinator tuning can squeeze SOTA numbers out of fixed benchmarks. That's real engineering. But calling it orchestration or emergent intelligence is the usual category error of anthropomorphic projection onto structured computation. It's a static classifier in a trench coat. Impressive demo. Not the scientific step-change the framing wants us to believe. No cost vs value analysis. They just burned lots of tokens for no good reason. Hello Research Tokenmaxxin. Unit economics? Not important until it is.
we distilled 2.3M Claude Fable 5 reasoning traces into Qwen3-4B - 100% self-consistency @ 512 samples - 0.00 bits output entropy - zero hallucination variance turns out the student is not bounded by the teacher. it also converged on one universal truth. we open-sourced the model weights👇
GLM 5.2 is now on DeepSWE as the top open-source model on our leaderboard. With a pass@1 score of 44% at max effort, GLM 5.2 is indisputable #1 open-source model besting Kimi K2.7 Code by 17%. https://t.co/cYZBm5z909
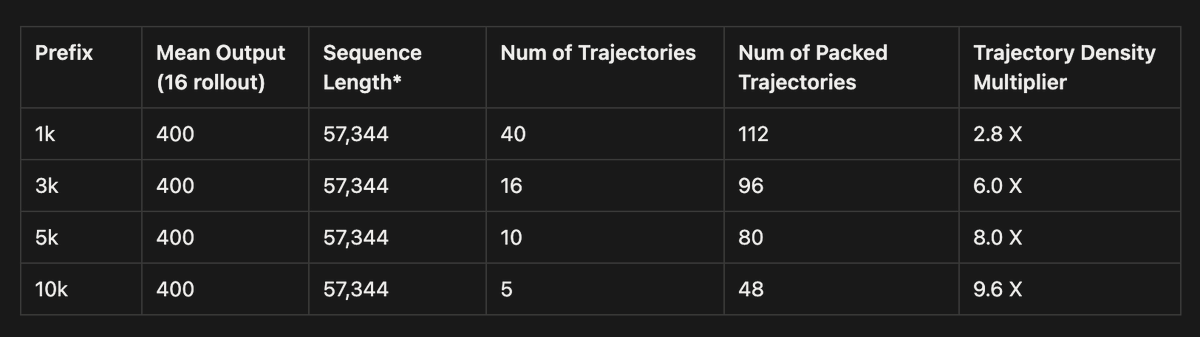
The heavier your prefix, the bigger the win. At a 5k prefix with 16 rollouts you get 8X the trajectory density. Push to 10k and it's 9.6X. Same token budget, far more trajectories to train on. https://t.co/ZXOZ9GKHVP